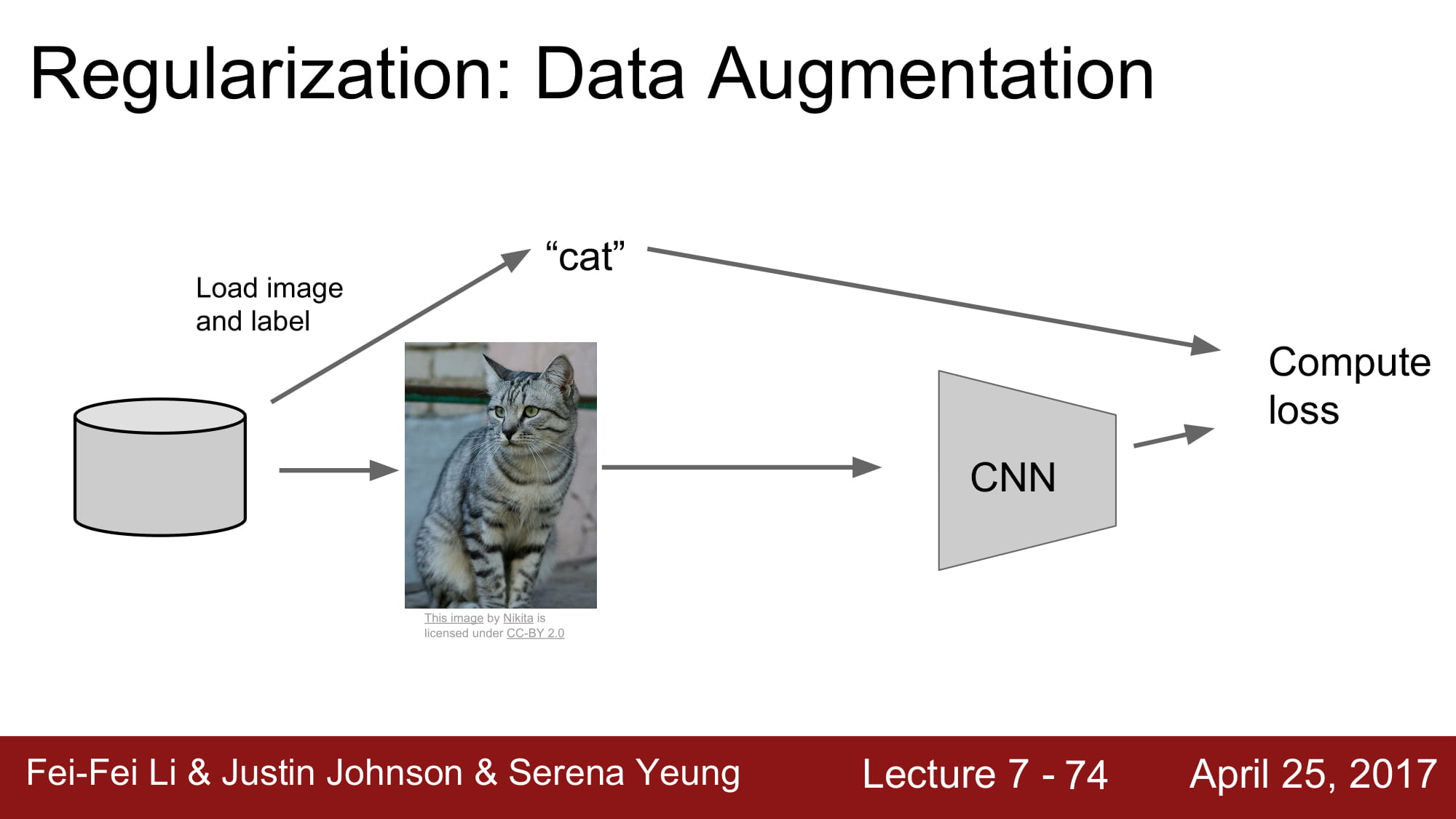
또 하나의 regularization 방법이 있는데, 바로 data augmentation 입니다.
input 값들을 조금씩 변형해서 데이터를 늘리는 방법입니다.
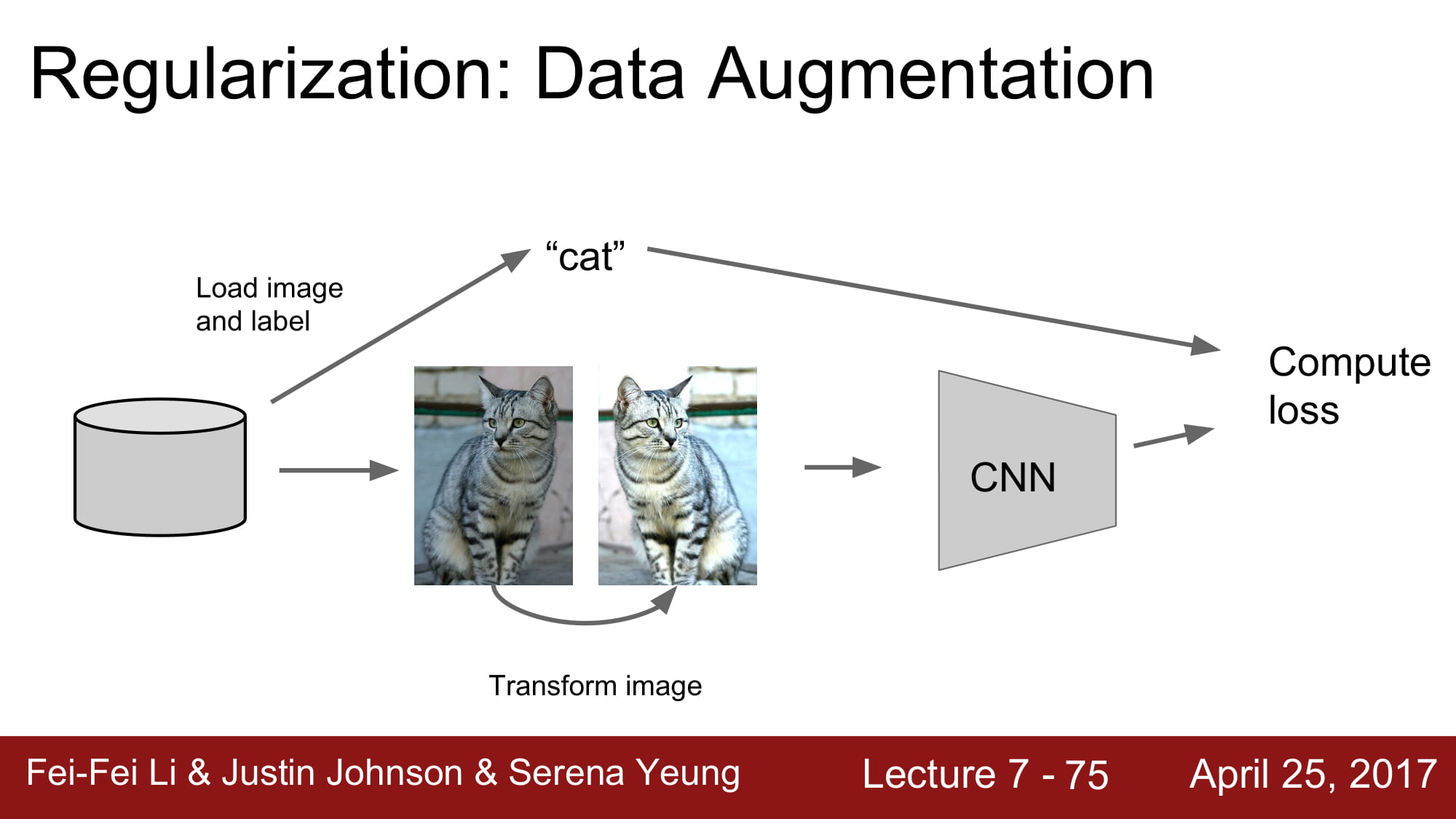


데이터를 좌우 반전하든, 조금 밝게 하든 고양이는 똑같은 고양이니까요!
이렇게 데이터를 변형해서 데이터를 늘려서 정규화 시키는 방식도 있습니다.
또한 조금 더 정교하게는 PCA를 적용하여 RGB 값을 변형하여 학습시키는 방식도 있습니다.

또는 이미지를 다양한 size 로 crop 해서 사용할 수도 있습니다.
고양이의 일부분도 고양이니까요!
이렇게 학습시킨것은 test 할때 여러가지 sacle의 image 를 만들고 거기서 (4가지 코너 + 1가지 중앙 ) * 2( flip ) 을 넣어서 test 합니다.

이 외에도 여러가지 input image 자체를 변경하는 방식들이 있다고합니다.
drop out 과 비슷하게 weight matrix 자체를 0으로 만들어 버리는 drop connect 라는 방식도 있다고 합니다.
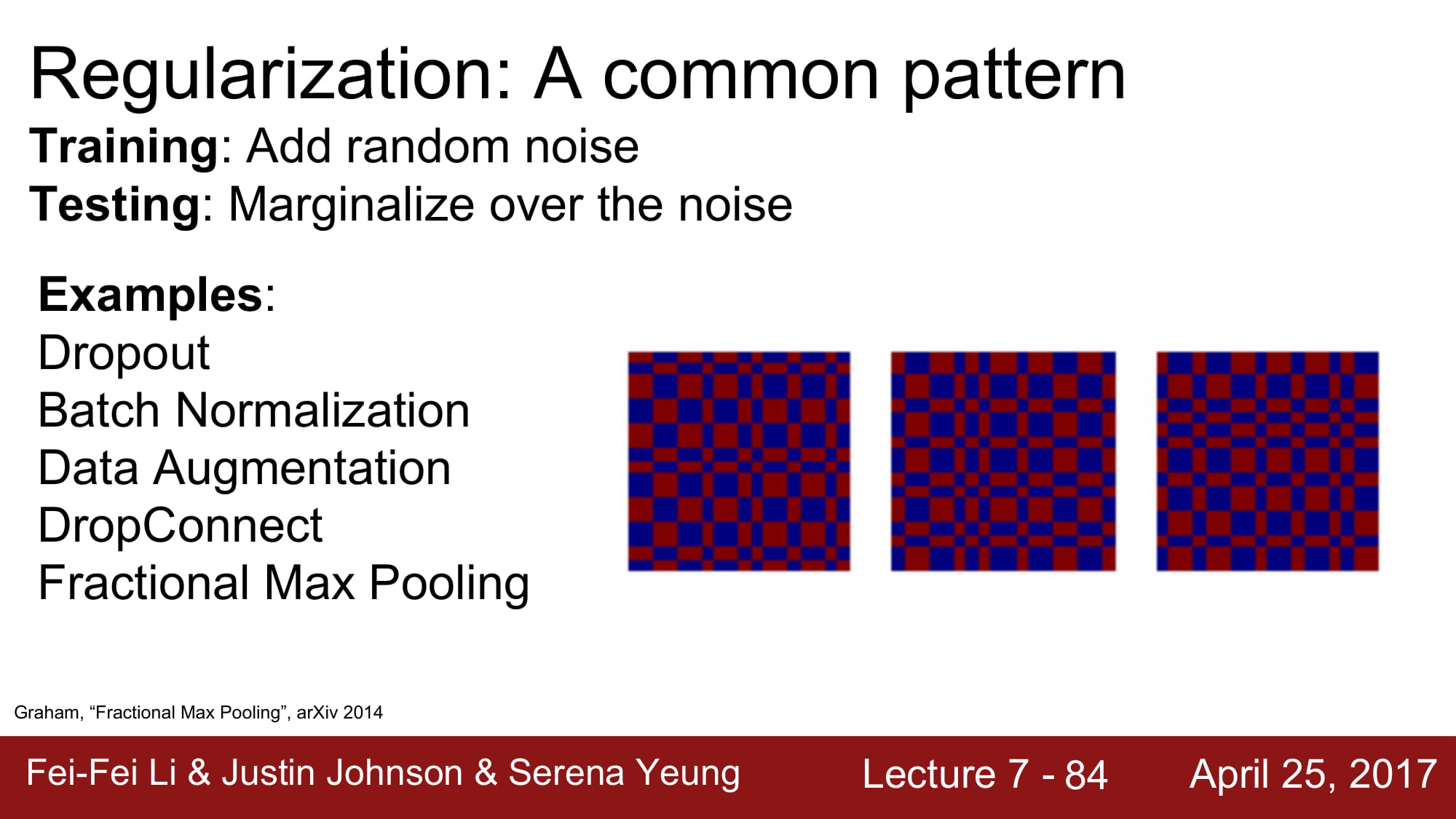
2*2 maxpolling 연산은 보통 고정된 지역에서 일어나는데, 오른쪽 그림처럼 랜덤한 지역에서 max pooling 을 진행하는것이 바로 fractional max poolling 이다.
test 시에는 이 randomness 를 없애주기위해 pooling region 을 고정시키거나, 여러개의 pooling region 을 만든 후 average out 하는 방식을 사용한다고 합니다.
http://scholar.google.co.kr/scholar_url?url=https://arxiv.org/pdf/1412.6071&hl=ko&sa=X&scisig=AAGBfm1OeH84lZvxeRlfDaGNCZ1lt7ftEg&nossl=1&oi=scholarr
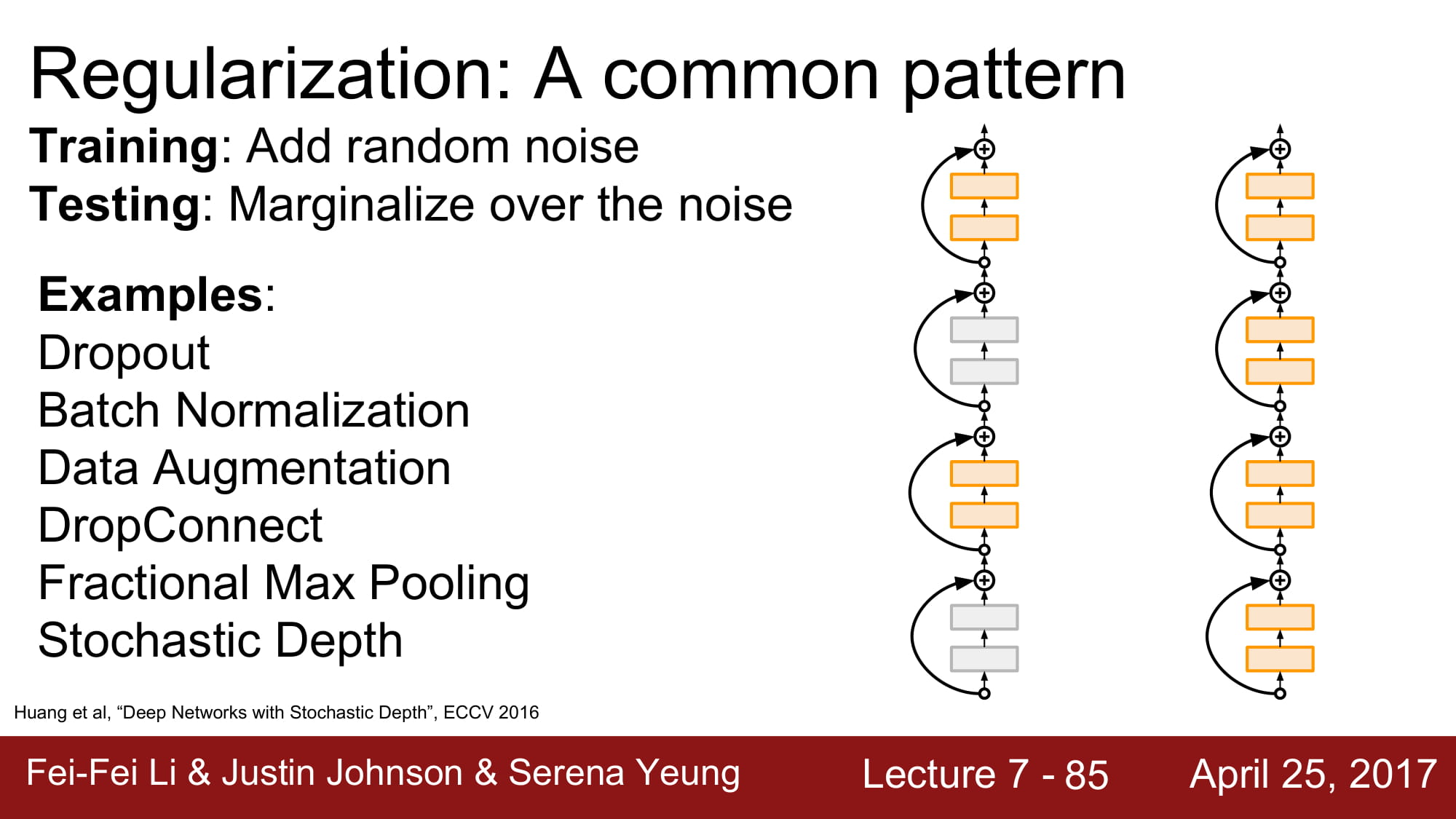
stochastic depth 는 학습시에 random 하게 layer 자체를 drop 시키고 test 할때는 전체 network 를 사용하는 방식입니다. drop out 과 효과는 비슷하다고 합니다. 똑같이 drop을 통해 noise 를 주는 방식인것같네요.
보통 깊은 DNN 을 할때는 BN 을 기본적을 사용한다고 합니다. 그 이유는 Optimizer 를 도와주는것이 학습에 용이하기 때문이라고 하고, input distribution 을 정규화 하면서 지나치게 영향력이 큰 node 에 대한 영향력을 낮춰주는 효과도 있기 때문입니다.
하지만 이 BN 을 통해서 정규화가 이루어지지 않았을경우 Drop out 을 추가하셔 정규화를 진행한다고 합니다.
Drop out 은 그냥 생각해봐도 아예 랜덤으로 버리고 시작하니까 정규화가 안될리야 안될수 없네요.
위에 BN 에 대해서도 적어뒀지만, Drop out 과 BN 이 같은 효과를 가져온다고는 하지만 상세하게 역활이 조금 다릅니다.
DNN 의 효율성과 빠른 학습을 위해 BN 을 기본적으로 사용하고, 정규화가 추가적으로 필요할때 Drop out 을 사용해봅시다.