그럼 RNN 이 어떻게 작동하는지 자세히 알아보자.
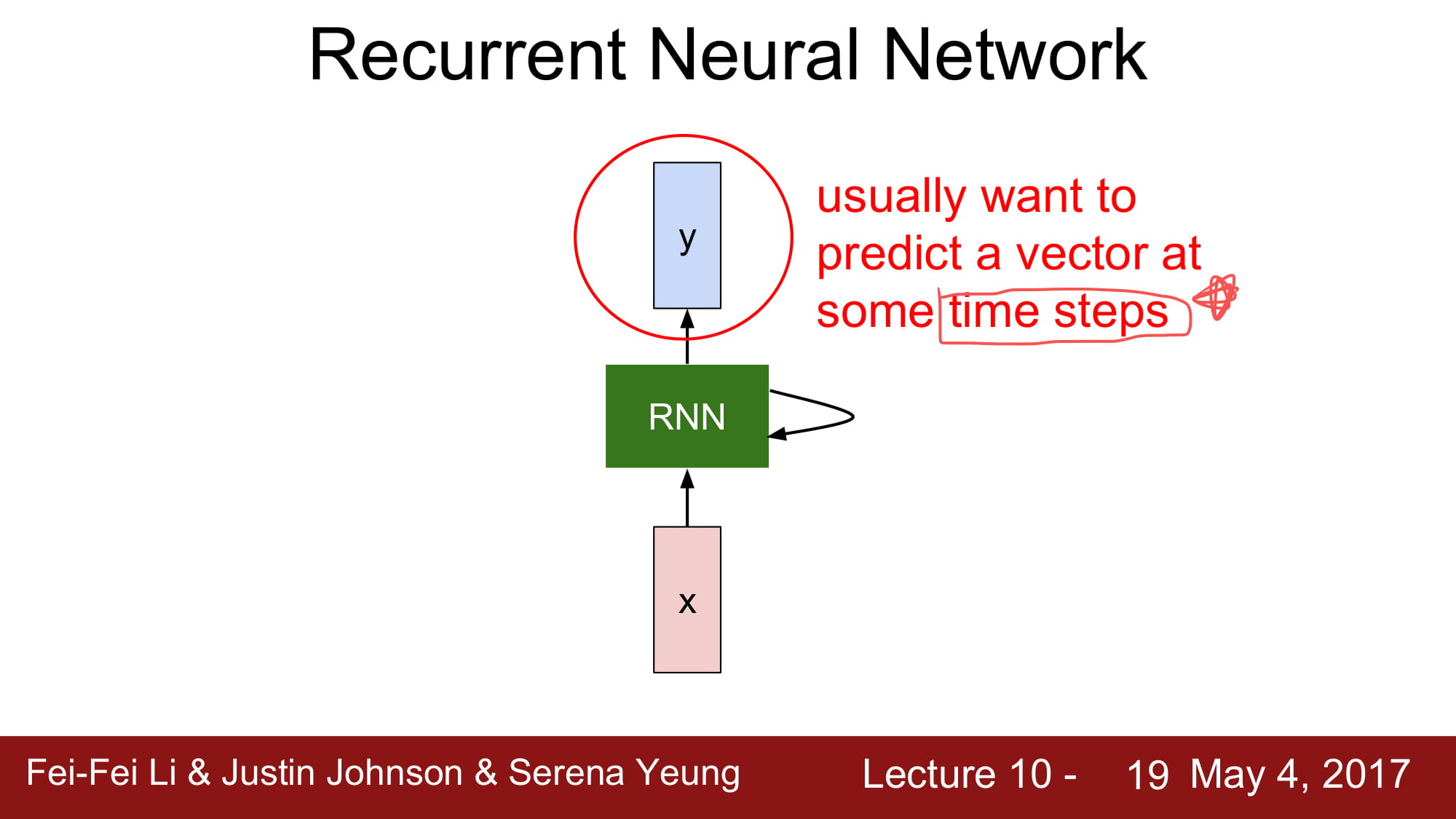
RNN 은 주로 특정 time step 에서 특정 vector 를 예측할때 사용한다.
말 그대로 순환적인 구조를 가진다.
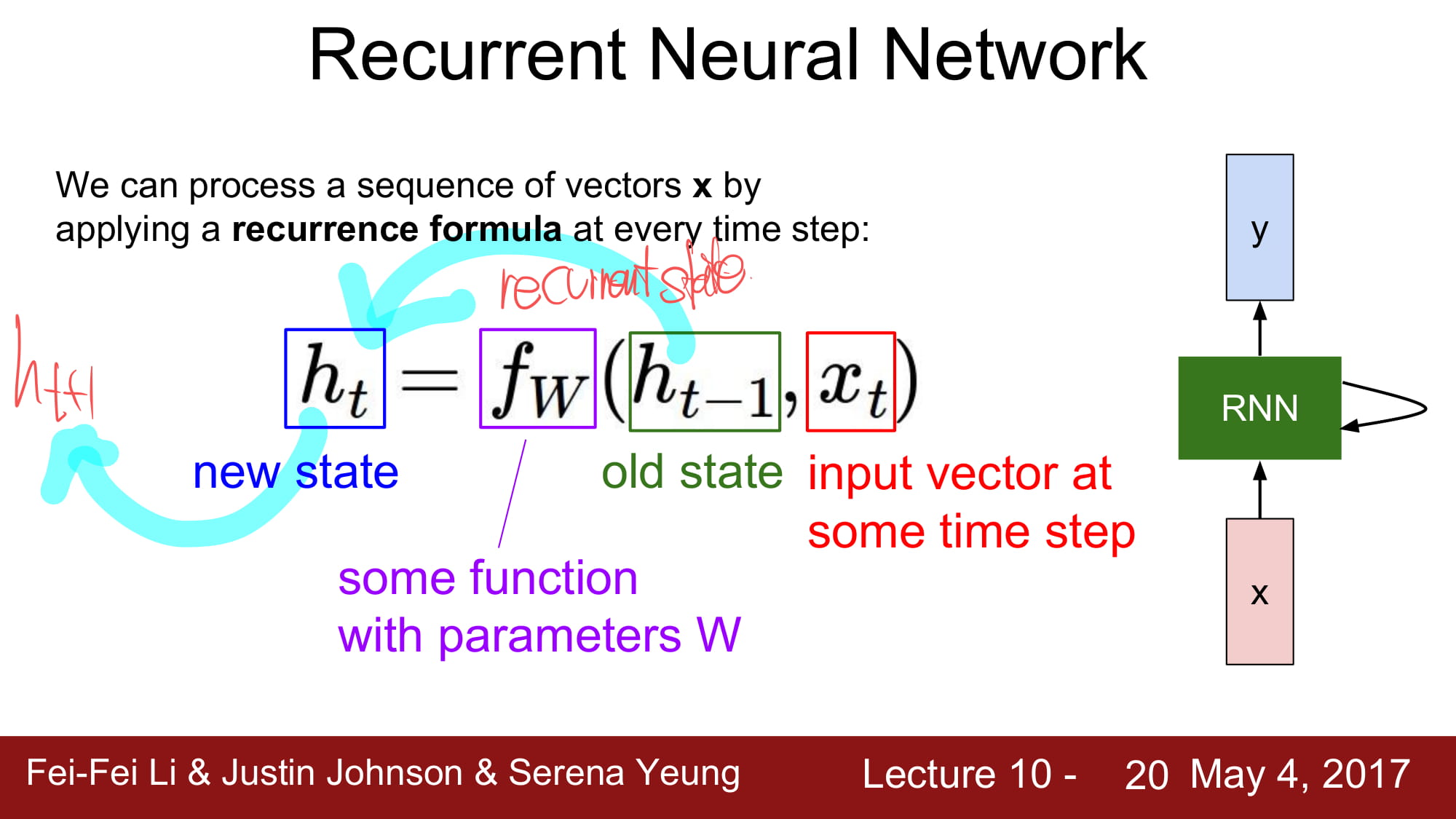
재귀적으로 함수를 호출하는것처럼, 재귀적으로 이전값을 불러 사용한다.

주의할점은, 재귀의 반복 안에서 항상 같은 Weight 와 bias 를 사용한다는것이다.

그리고 activation 은 tanh 를 사용한다.
왜 tanh 를 사용하는지는 위의 필기에 적어둔것처럼, 항상 같은 Weight 와 bias 를 사용하기 때문이다.
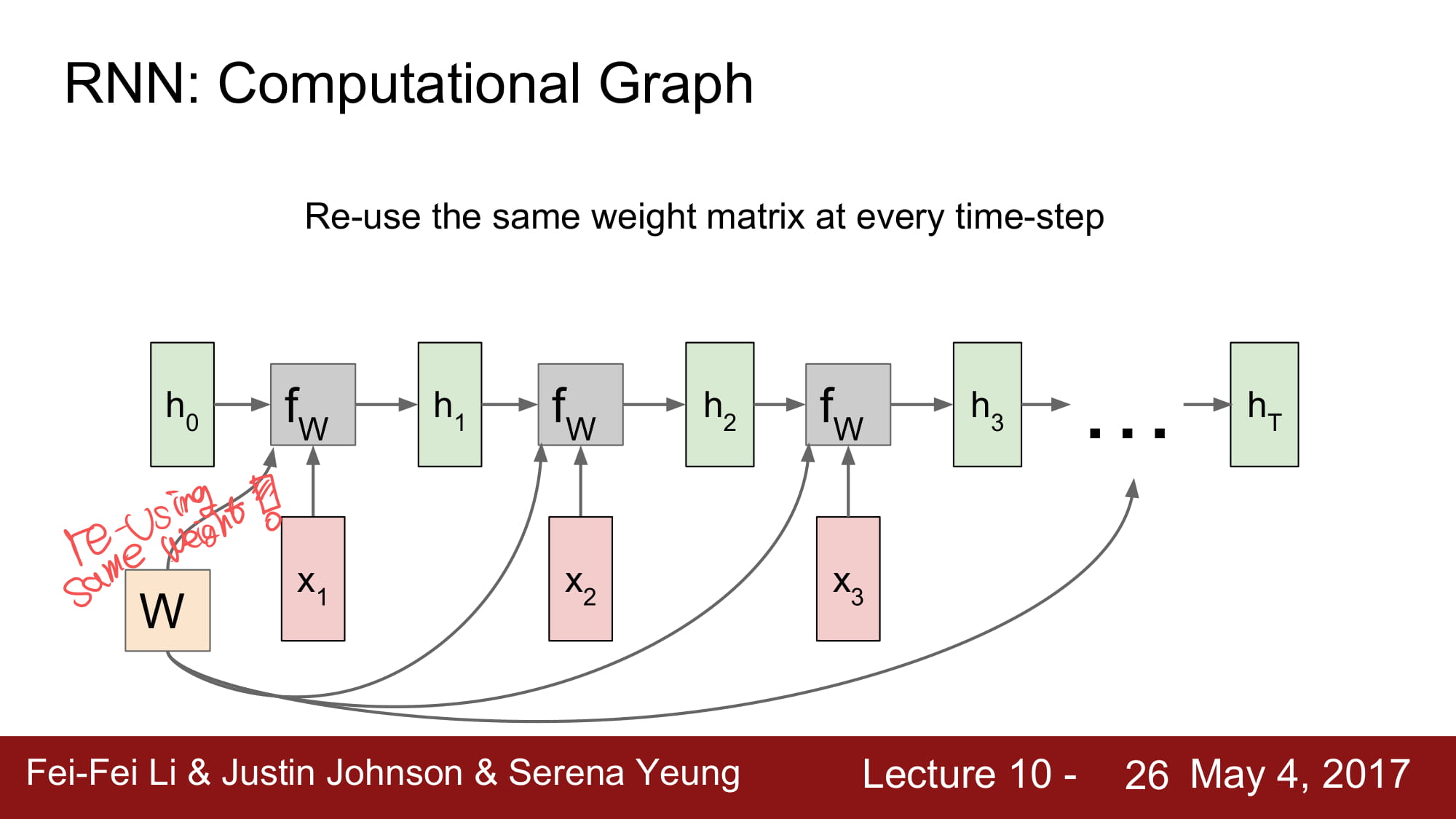
계속 설명하는거지만, Weight 가 어떻게 공유되는지 위와같은 그림으로 설명할 수 있다.
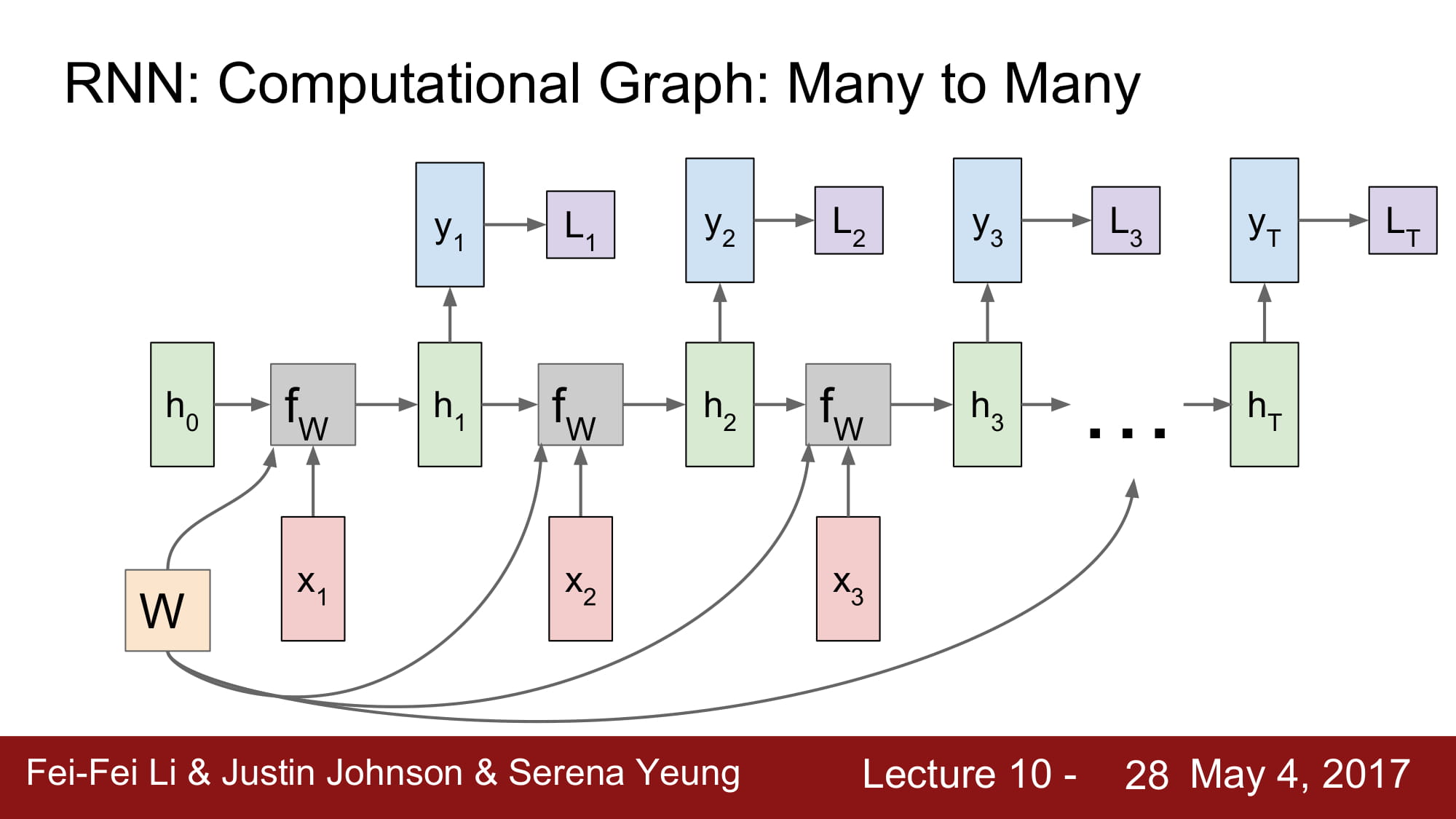
그럼 loss 를 어떻게 구하며, back prop 은 어떻게 진행할까?
일단 local vector 에서 각각 local loss 를 구하게 된다.
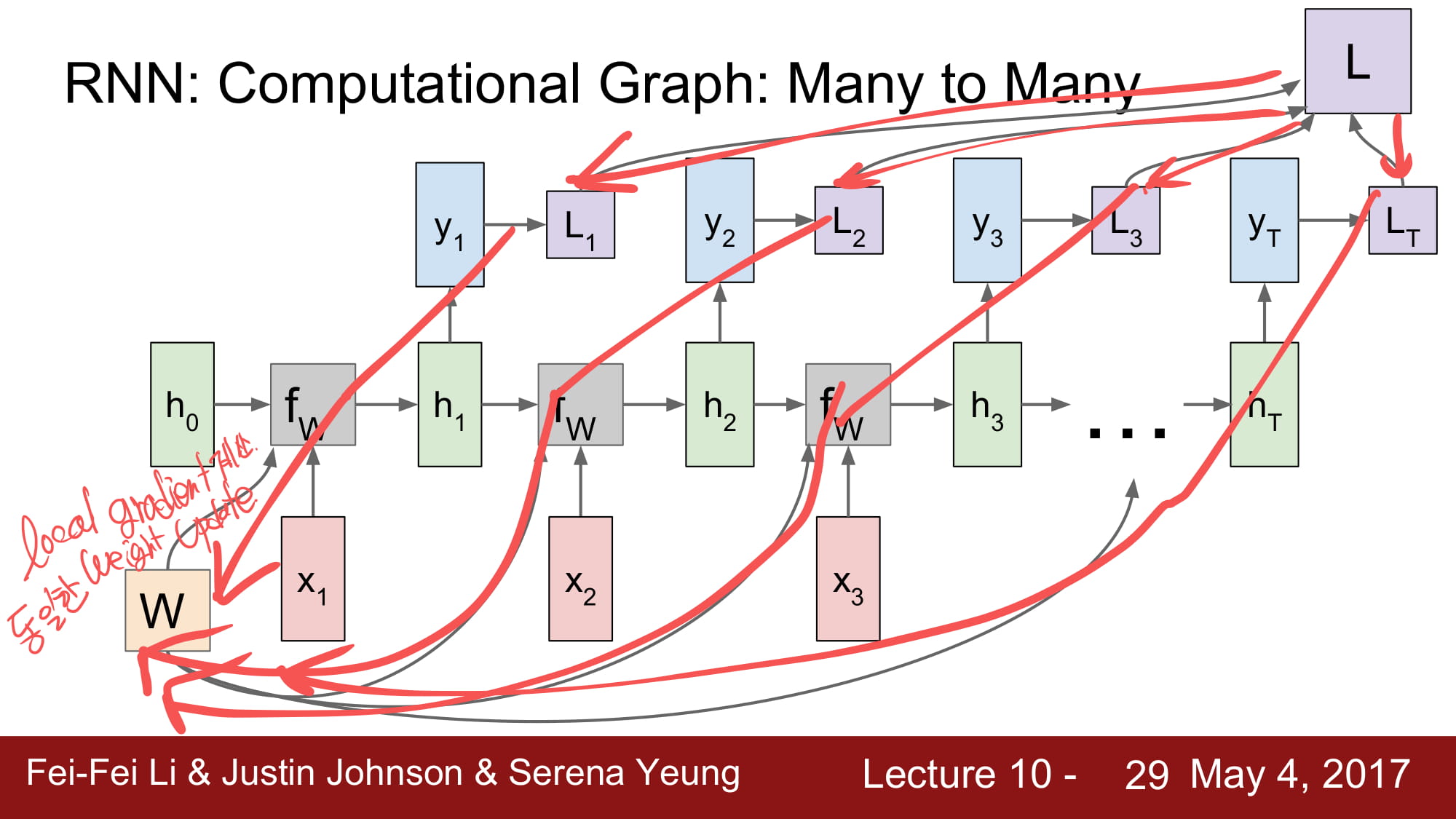
그리고 total loss 를 구하고, 다시 뒤로 흘려주게된다.
각각 local gradient 를 구하지만, 동일한 weight 에 update 하게된다.
동일한 W 를 계속 곱해야하기 때문에, tanh 를 사용한것이다.
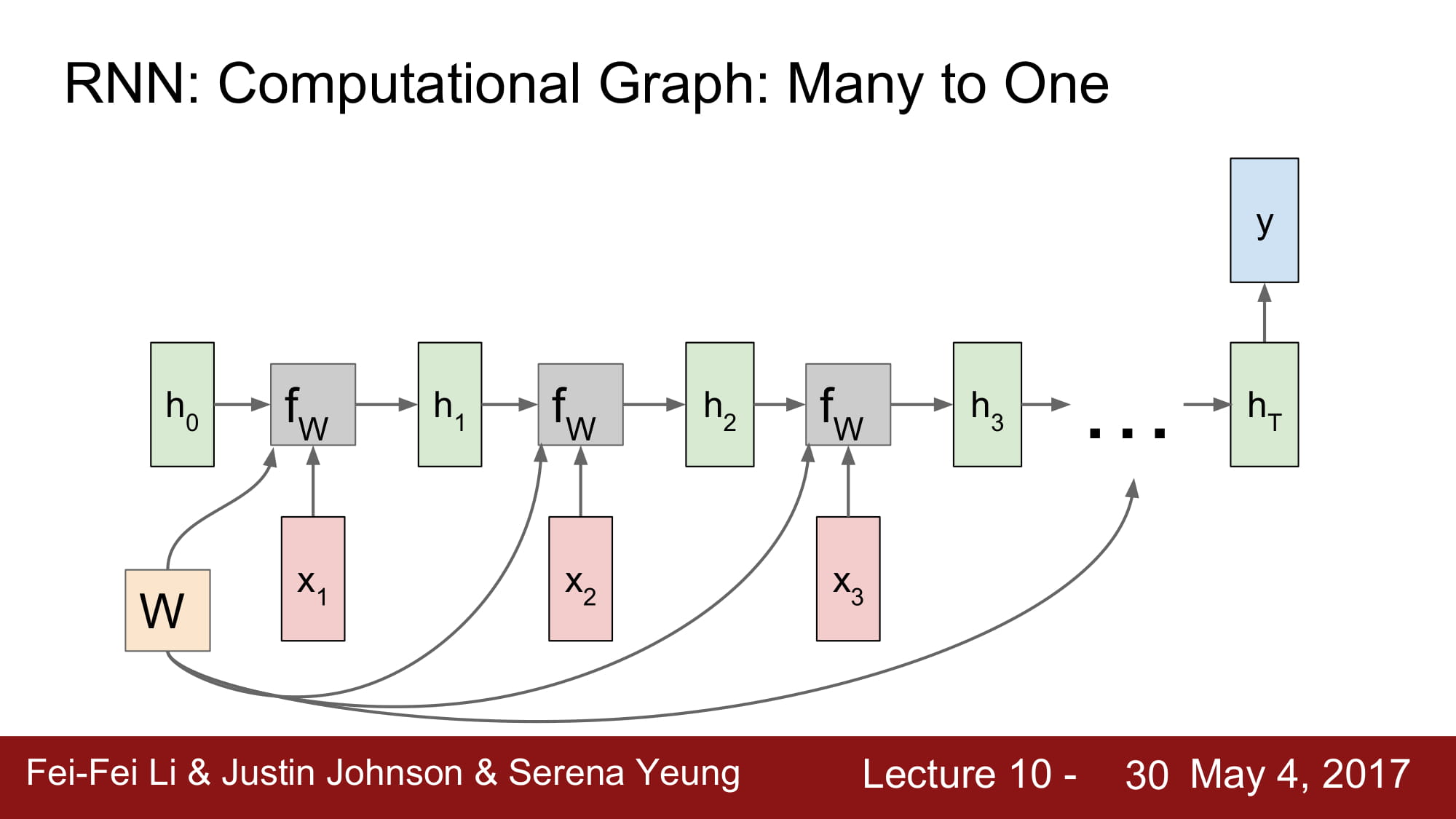
초반의 모델의 설명을 조금 더 자세하게 풀어놓은것이다.
N:1 구조에서 똑같이 W 를 공유하고, 마지막에 predict vector Y 가 나온것을 볼 수 있다.
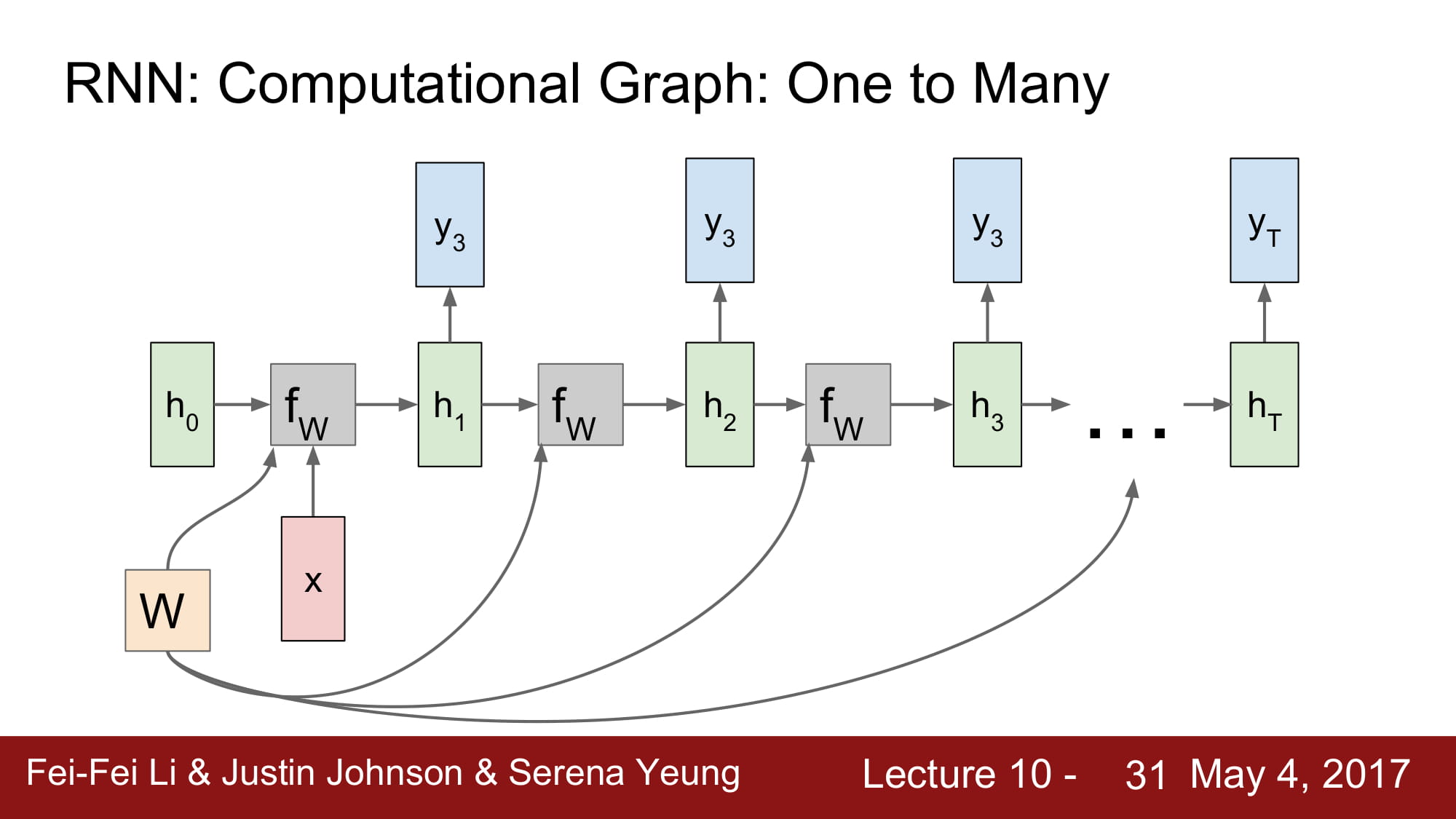
1:N 모델은 입력이 첫 번째에만 있고, 각각 W 들만 계속 곱해주는 형식으로 진행된다.
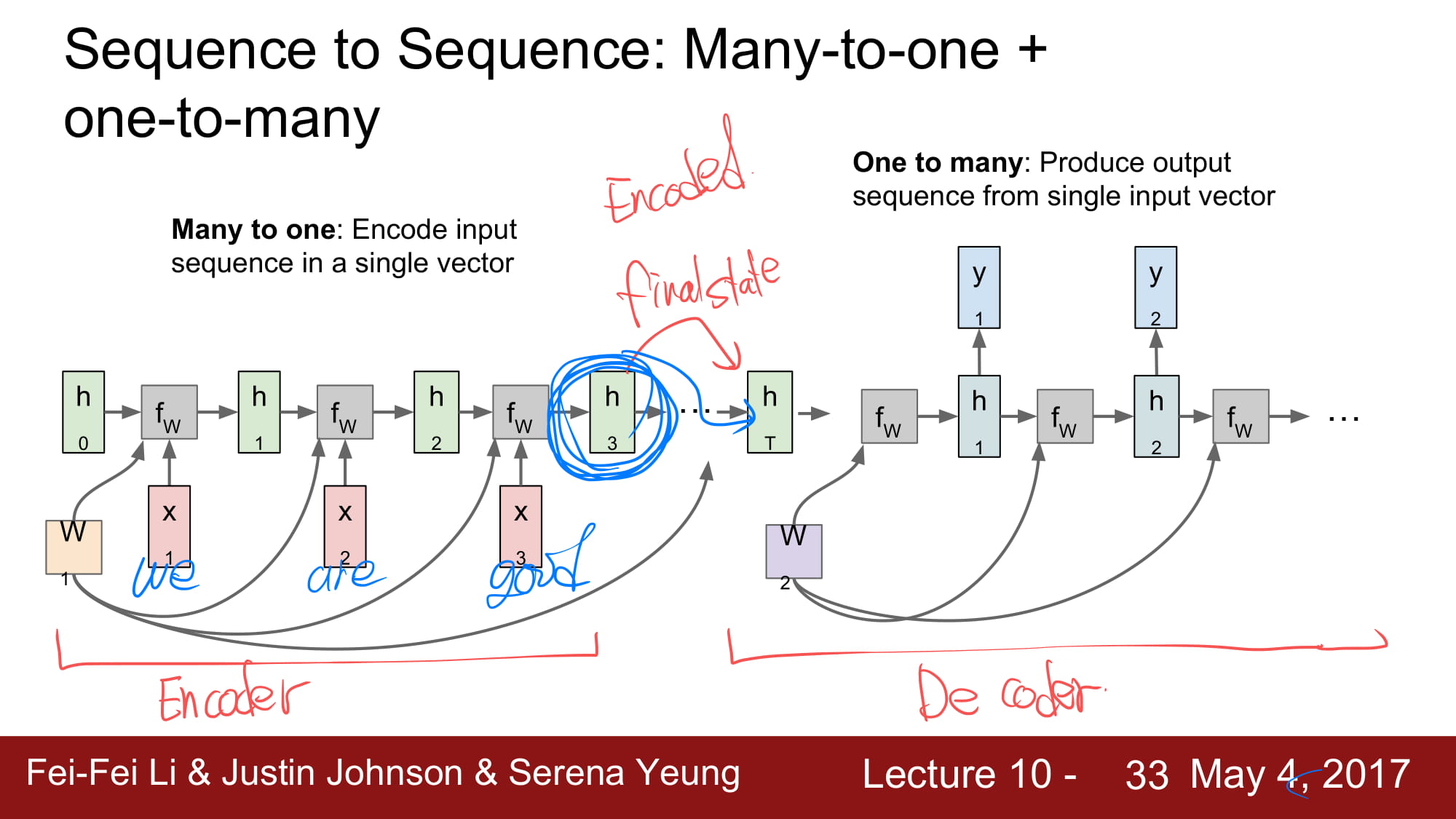
이 두개를 합치면, 그 유명한 Encoder & Decoder 가 된다.
N:1 으로 encoding 한 final state 를 decoder 로 넘기게되면 decoder 는 여러 결과를 도출하게된다.
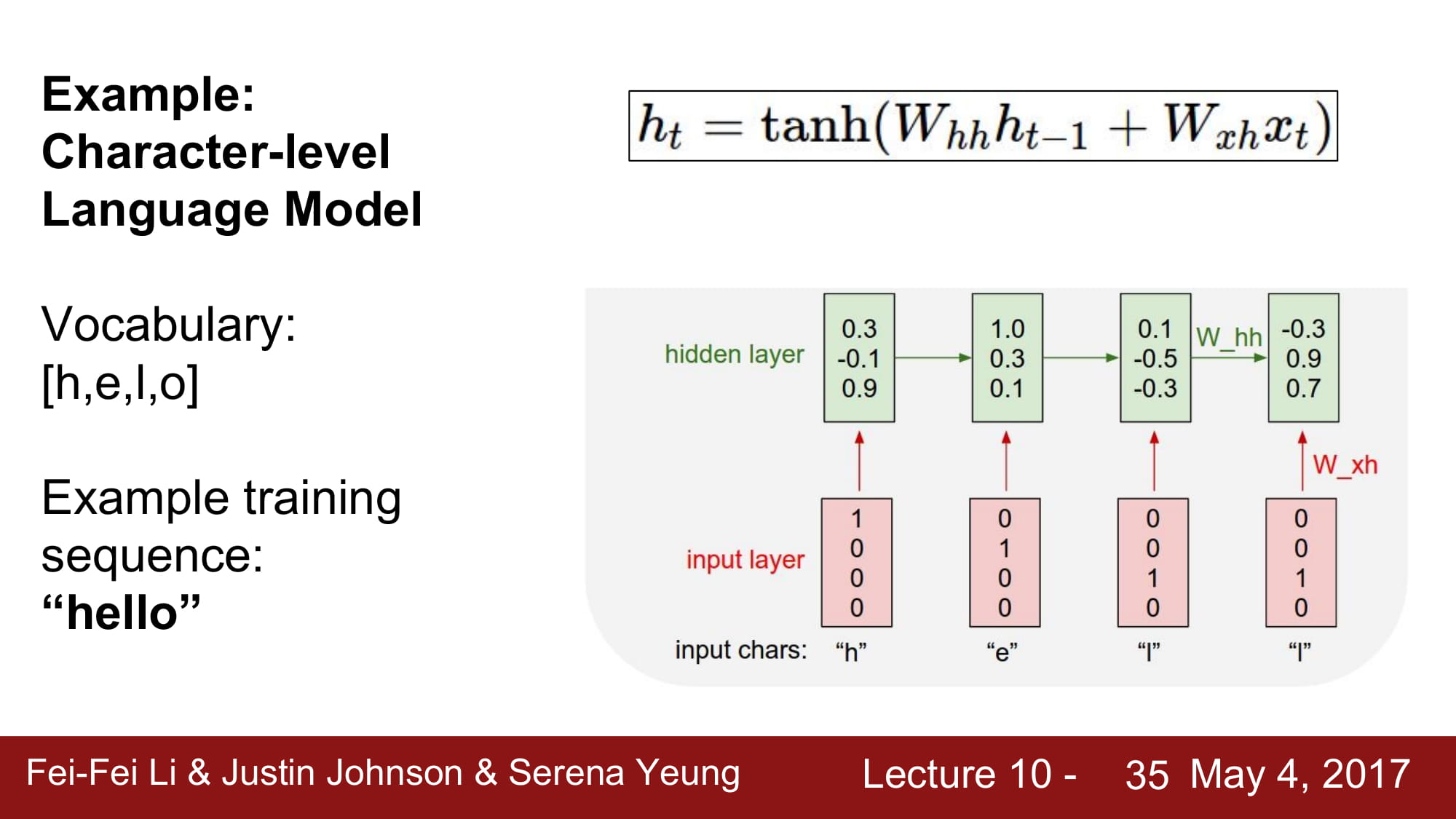
character-level Languate Model 을 예시로 공부해보자.
각각 h,e,l,o 는 one hot encoding 으로 vector 로 변환되어있고, 이를 RNN cell 에 태우게된다.
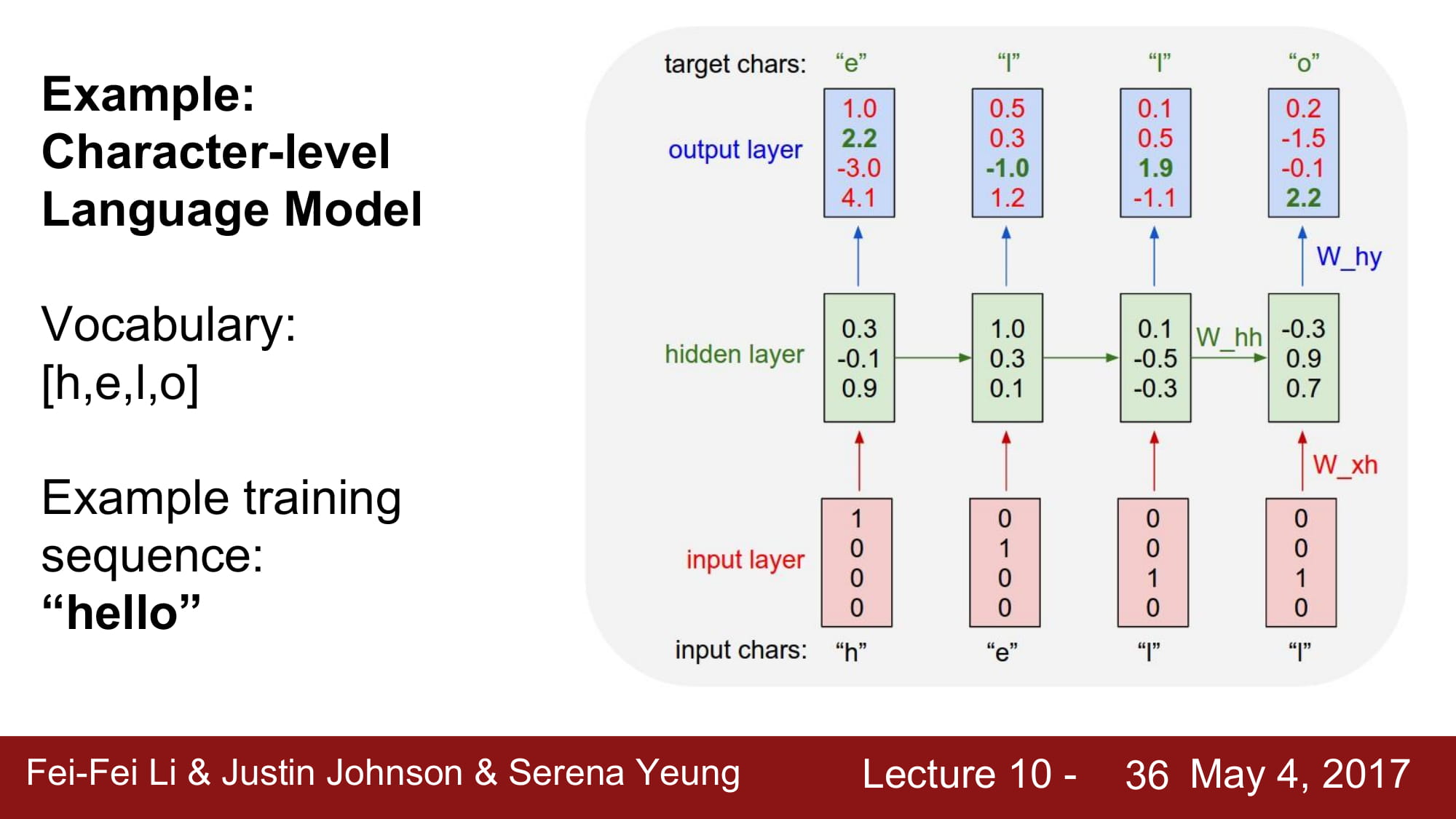
다음 글자를 예측하는 모델을 학습한다면, Many-Many 모델을 사용하게 될것이고
매 예측이 끝날때마다 각각의 hidden state 모두에게 loss 를 흘려서 local gradient 를 통해 W 를 학습할 것이다.
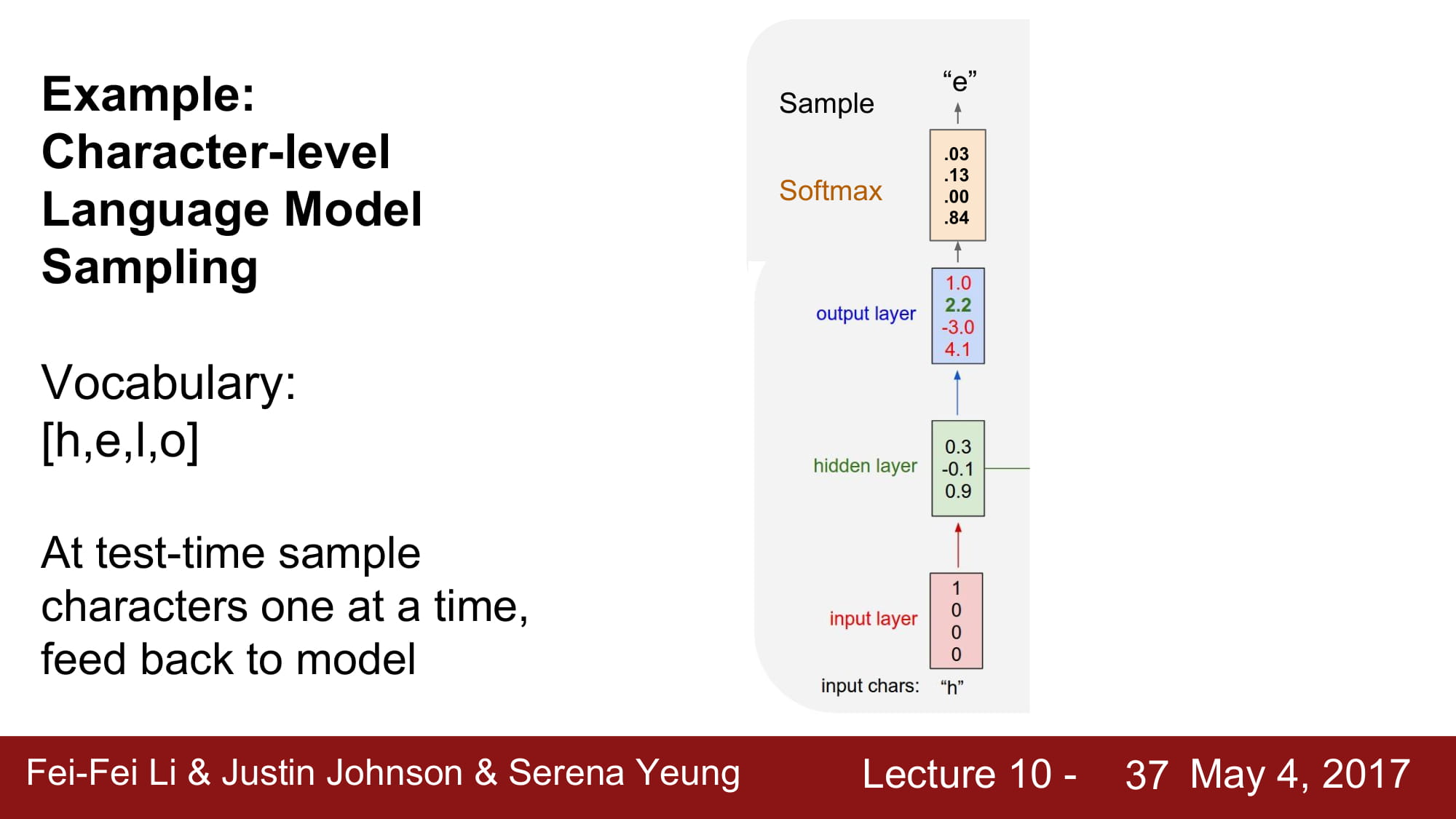
최종 예측은 softmax 를 통해서 한다. multi-class classification 이니 보편적인 softmax 를 사용한것같다.
여기서 softmax 를 사용하는 이유는 무엇일까?
예전에 배운것같지만, 다시 배워보면, 단순 score 비교 보다 확률 분포 안에서
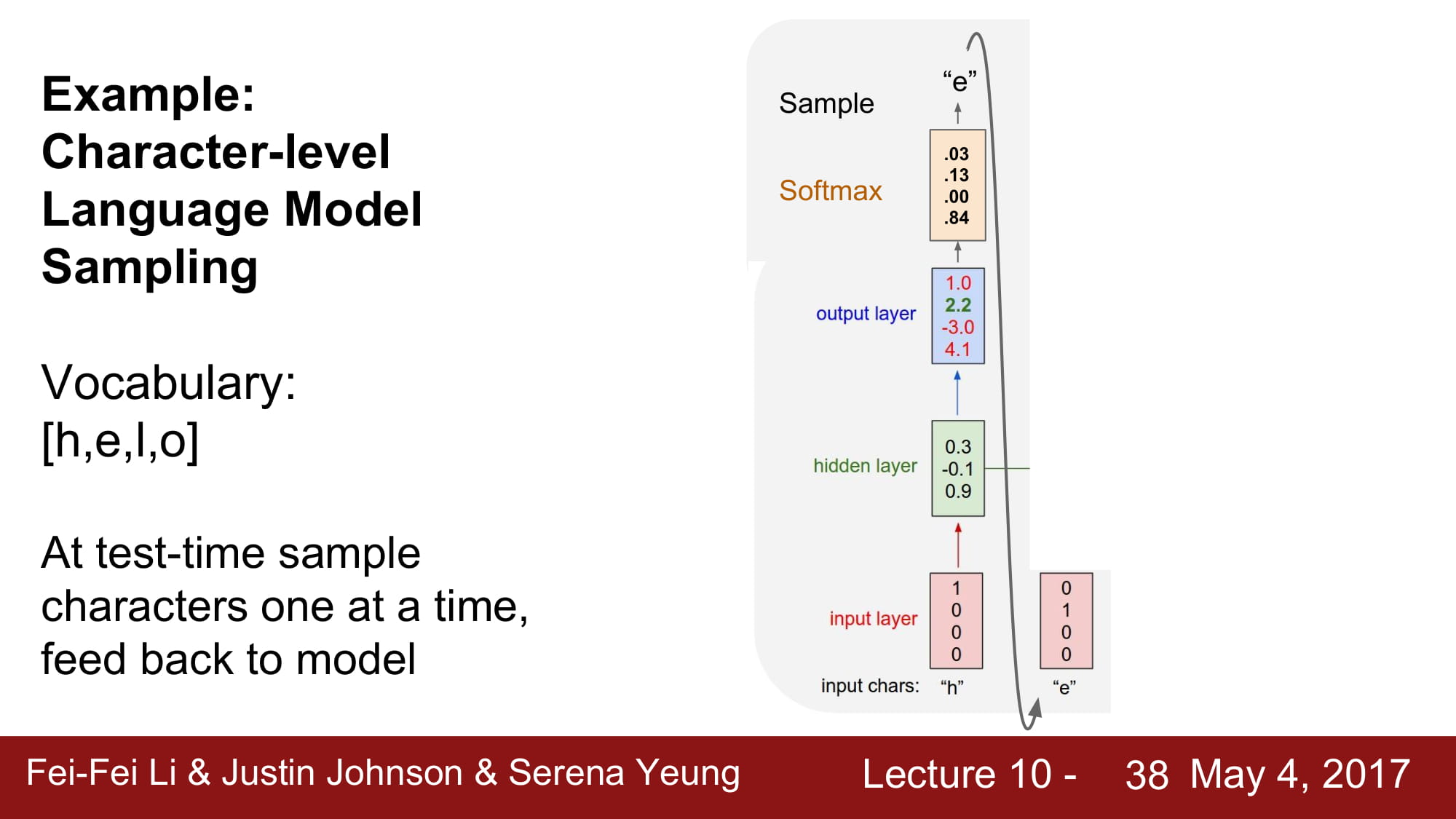
Test time 일때는, 최종 결과를 다음으로 넘겨줌으로써 다음 결과를 테스트할 수 있게 환경을 조성해준다.
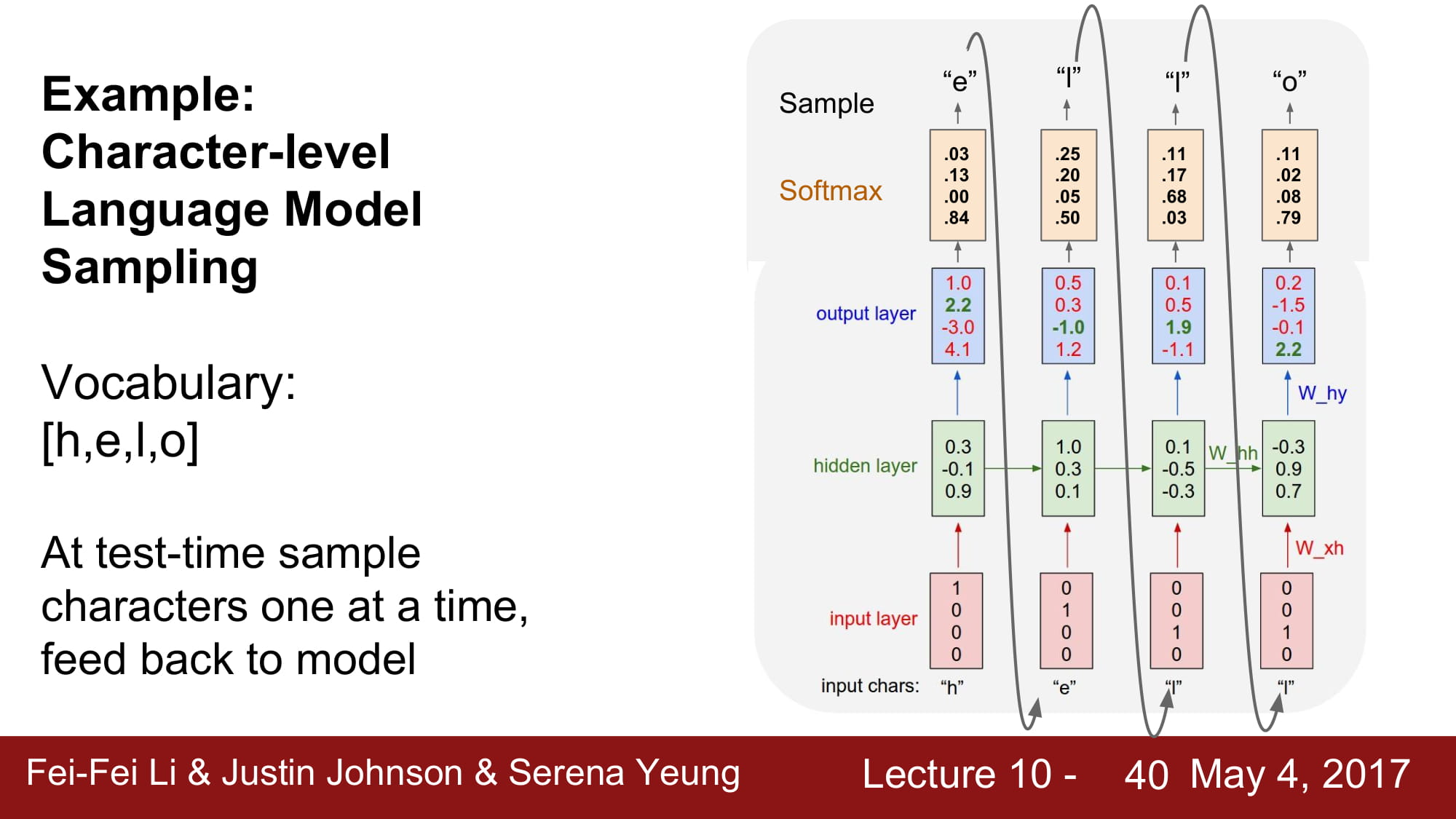
이걸 최종 Rnn length 까지 반복해주고 Test 의 결과를 보여주게된다.
Loss 는 Cross-Entropy 를 사용하여 구하게 된다.
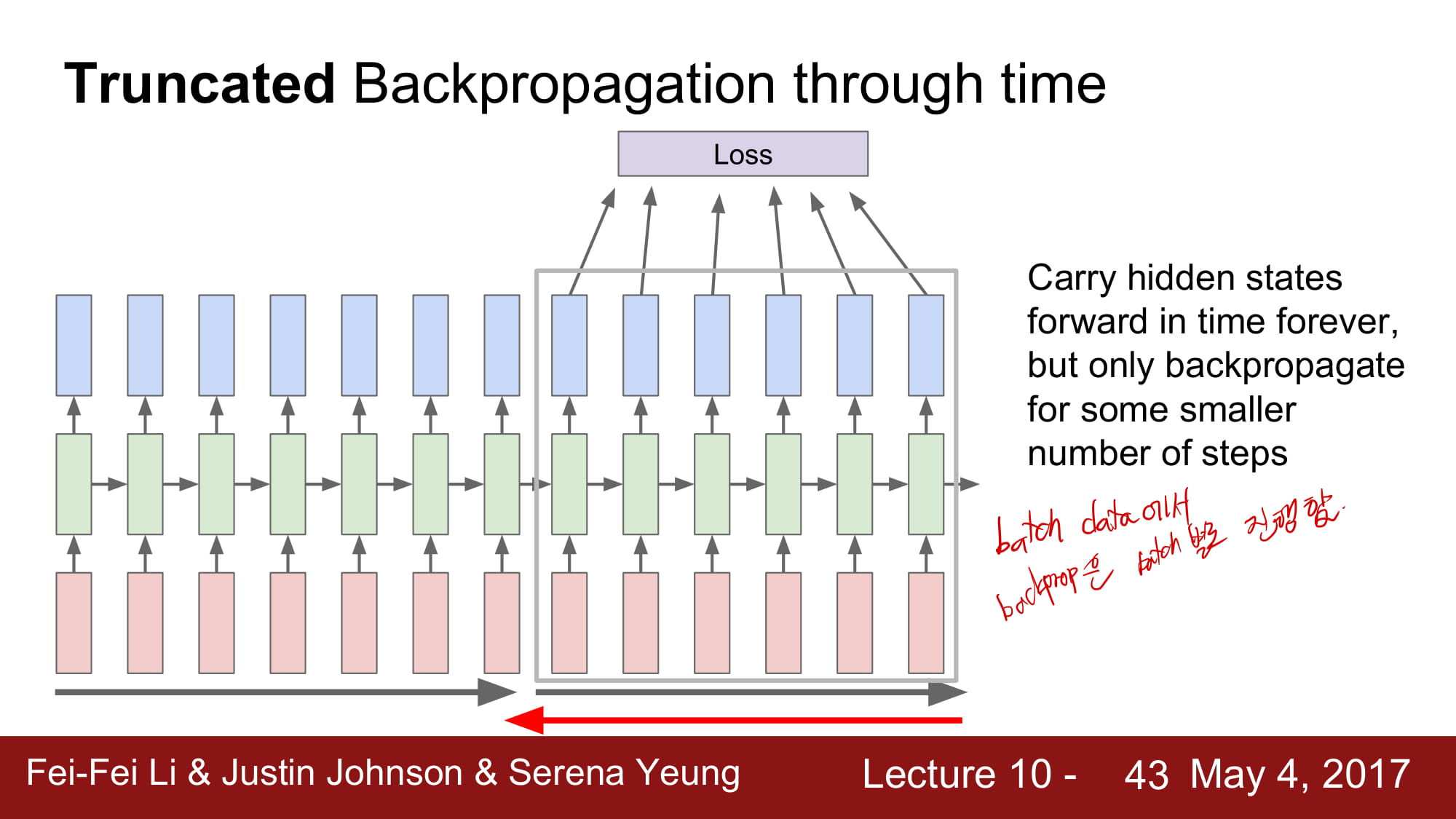
느린 학습속도와 많은 양의 memory 를 요구하는것을 해결하기위해, batch 단위로 학습을 진행함.