
Production 에 ML service 를 deploy 하기 위해서 어떤 일을 해야할까?
사실 일반적으로 생각하는것는 모델을 만드는 코드를 짜고 러닝을 시킨 후, 검증한다 정도가 떠오를 것이다.
하지만 실제 production 에 가기 위해서는, 거쳐야할 산이 너무나도 많다.
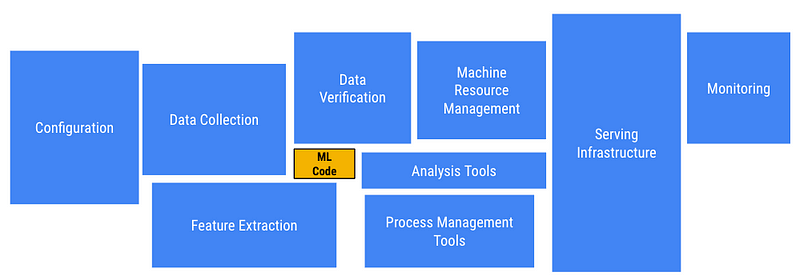
실제 ML 서비스로 갈때 거치는 문제들을 크게 3가지 파트로 나눌 수 있다.
- 데이터 수집
- 데이터 검증 및 학습
- 운영 서버 배포
자, 머신러닝 프로젝트를 한다 하면, 1번과 2번은 당연하게 생각하고 진행할 것이다.
모든 러닝이 끝나고 만족스러운 결과를 뽑아냈다 하면, 이제 다시 고민이 생긴다.
그래서 이거 어떻게 서비스로 올리지??
개발을 처음 배울때, 서버를 짜고 ftp 로 코드를 올리는 무식한 방법을 썻던것처럼, 처음 했던 프로젝트의 모델을 s3에 업로드 한 후 (그나마 s3 는 썻다..) 받아서 flask 로 그냥 돌리고 끝이였다.
이게 만약 production level 이였다면, 정말 큰 문제가 있을것이다.
- scalable 하지 않다.
- 이중화 되어있지 않다
- deploy 가 매우매우 힘들고 귀찮다.
사실 위 문제점들은 백엔드 개발에서는 docker 라는 시스템으로 어느정도 해결이 되었다.
또한, Data pipeline 에 따라 지속적으로 데이터를 수집하고 학습해야하는 경우, 위의 방법처럼 deploy 하는 방식은 너무 피곤한 일이 된다.
따라서 meachine learning service 에 필요한 component 들을 pipeline 으로 구성하여 사용해야 한다.
하지만 저 많은 시스템을 머신러닝 엔지니어가 모두 하기에는 무리가 있고, 백엔드 개발자, 데브옵스, 머신 러닝 개발자가 모여 같이 개발 해야한다.
규모가 작은 스타트업일 경우, 이러한 pipeline 을 구축하기 힘들 뿐더러, 구축하는데 시간이 오래 걸릴 수 있다는 문제도 있다.
이러한 infrastructure 를 kubernetes 위에서 자동으로 구축해주는 오픈소스 프로젝트가 바로 kubeflow 이다.meachine learning service 에 필요한 단계들을 패키징 하여 한번에 제공하는 것이다.
Kubeflow 는 kubernetes 위에서 인프라를 구성하기 때문에 Logging system, monitoring system, APM, replication, Healthcheck, 자원의 효율성, Container 등의 좋은 장점들을 다 가져올 수 있었다.

참고
https://codelabs.developers.google.com/codelabs/kubeflow-introduction/index.html#1
http://swalloow.github.io/eks-kubeflow
https://medium.com/kubeflow/why-kubeflow-in-your-infrastructure-56b8fabf1f3e
https://kubernetes.io/blog/2018/06/07/dynamic-ingress-in-kubernetes/