Codes: https://strutive07.github.io/assets/images/3_4_Naive_Bayes_Classifier_Application_Matlab_Code/Week_3.zip Files: https://strutive07.github.io/assets/images/3_4_Naive_Bayes_Classifier_Application_Matlab_Code/IE661-Week_3-Part_3-icmoon-ver-1.pdf last update datetime: Jan 12, 2020 12:53 PM

리뷰에 대한 sentiment analysis 를 진행해보자.
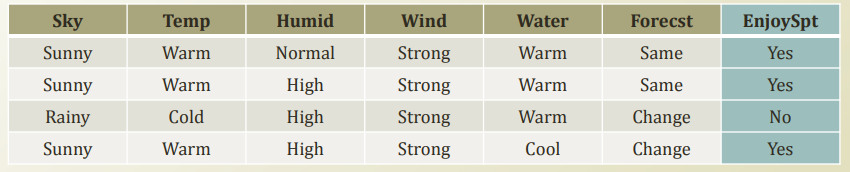
기존에는 feature들을 임의로 이런식으로 정의했는데, text 데이터에서는 어떻게 feature를 정의할 수 있을까?
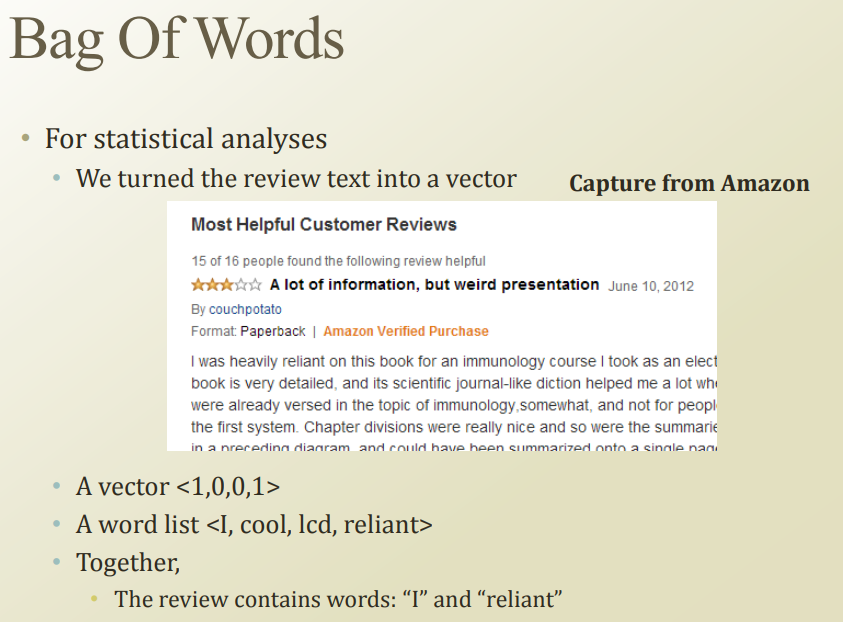
text 에서는 Bag of words 방식으로 feature를 정의한다.
Dictionary에 단어를 등록해두고, 문장내에서 해당 단어가 등장했는지를, 또는 얼마나 많이 등장했느지 등등을 사용할 수 있다.

이번 데이터에서는 198개의 document, 대략 3만개의 unique word가 존재한다.
나이브 베이즈 분류기이기 때문에 각 단어간의 correlation은 무시한다.