Files: https://strutive07.github.io/assets/images/4_7_Naive_Bayes_to_Logistic_Regression/IE661-Week_4-Part_3-icmoon-ver-1.pdf last update datetime: Jan 19, 2020 3:18 PM
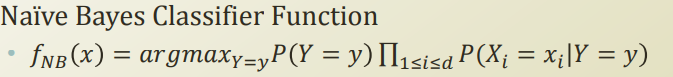
기존 나이브 베이즈 분류기는 Y 와 X 간에 Y 가 모든 feature의 latent variable이란 가정으로 conditional independent 을 만들어서 분류기를 만들었다.
Gaussian Naive bayes
각 feature들이 continuous random variable 이라면? 우리는 각 variable이 gaussian distribution을 따른다고 가정할 수 있을것이다. 또한 class varible이 보통 categorical variable 이므로 각 class variable들에 대해서 mean 과 variance또한 구할 수 있을것이다.
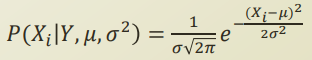
또한 Y 에 대한 prior 정보는 여전히 categorical variable 이므로 MLE, MAP 등의 방식으로 간단히 구할 수 있을것이다.
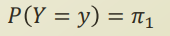
최종적으로 gaussian naive bayes 는 다음과같은 식이 된다.
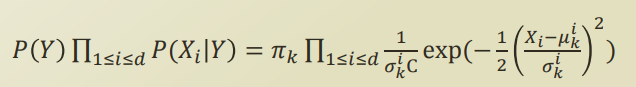
Derivation to Logistic Regression
Discriminative model vs Genrative model
gaussian naive bayes 를 미분할경우, logistic regression이 된다고 한다! 이걸 유도해보자.
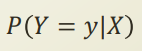
logistic regression에서는 위 value를 바로 구하려 했고, 이런 모델을 discriminative model 이라고 한다.
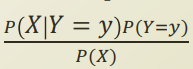
generative model은 이 방법을 보통 bayes 이론을 적용하여 구하게된다.
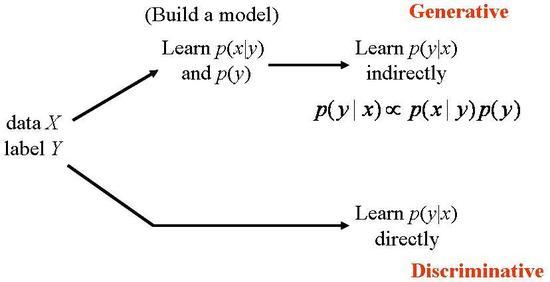
출처: https://sens.tistory.com/408
조금 더 부연설명을 하자면, generative 모델은 likelihood, prior, 각 class의 distribution 등 데이터를 학습해서, 모델이 데이터를 생성해낼 수 있는 모델이고, discriminative model은 두 class 가 주어진 경우, 이 class 의 차이점에 주목한다. 따라서 모델이 데이터를 생성할 수 없다.
예시가 있어서 가져옴
예시
- 임의의 문장이 어떤 언어인지를 판별하는 문제라고 하자.1) 모든 언어를 학습해서 그 지식을 기반으로 판별하는 것이 Generative approach이고,2) 언어를 학습하는 것이 아니라 문장들의 언어적 차이를 통해 판별하는 것이 Discriminant approach 이다.
- 어떤 시그널을 카테고라이징 한다고 하자. Generative algorithm: 데이터가 어떻게 생성되는지를 모델링한다. generation assumption에 기반해서, 어떤 카테고리가 이 시그널을 생성할 확률이 제일 높은가?Discriminative algorithm: 데이터가 어떻게 생성되었는지에 상관 없이, 단순히 이 데이터만을 보고 카테고라이징 한다.
출처: [khanrc’s blog]
https://khanrc.tistory.com/entry/Generative-model-vs-Discriminant-model
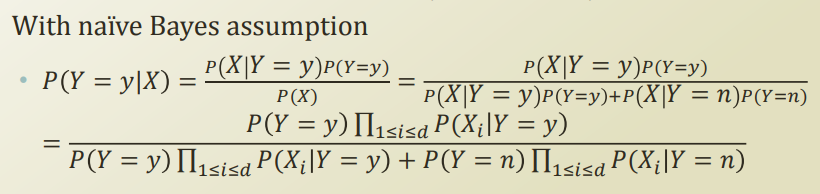
강의 예시에서 보면,
logistic regression은 discriminative model로, posterior 를 바로 학습하면서 각 class 간의 차이점을 학습하고.
나이브 베이즈 모델은 generative model 로 posterior를 바로 학습하지 않고, 이를 likelihood 와 prior로 나누어서 이를 각각 parameter를 주어서 학습시켜서 posterior를 유도한다.
마치 MLE vs MAP 와 유사하다.
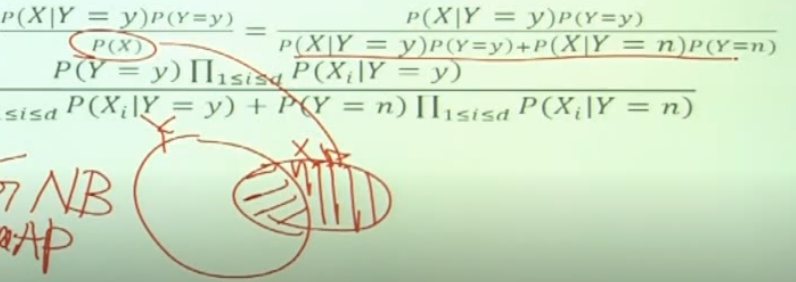
P(X) 는 Y 에 속해있는 X 와 그렇지 않은 X 로 나눌 수 있고, 이를 다음과같이 식을 전개할 수 있다.
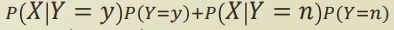
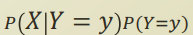
그리고, 이 식은 각 feature 간의 depedency때문에 parameter 개수가 exponential 하게 증가한다. 따라서 이걸 naive assumption을 사용하여 conditional independent 를 가정하면 다음과같이 식이 변형된다.
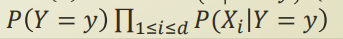
자, 그리고 우리가 위에서 정의했던 이 두 식을 적용해보자.
-
prior
-
gaussian naive bayes
적용
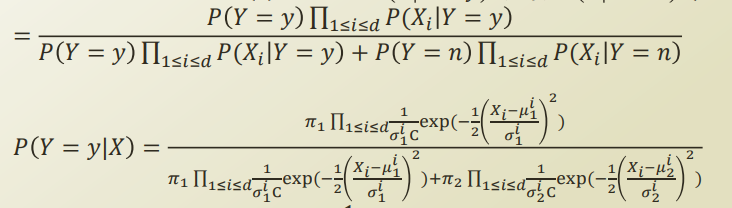
분자를 분자 분모에 나눠서 식을 전개하면 다음과같이 정리된다.
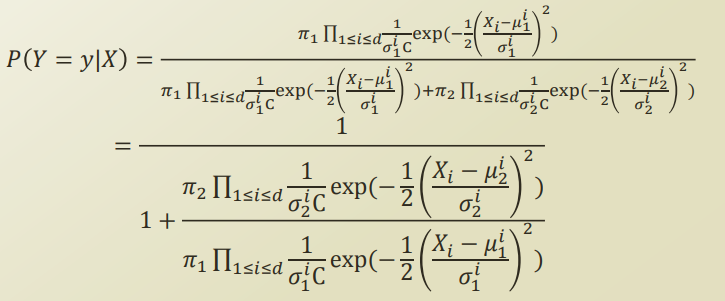
그 이후, 두 class 의 variance가 같다 라고 가정하고, 식을 정리해보자.
식의 이동이 말로 설명하기 힘들어 그림으로 설명.
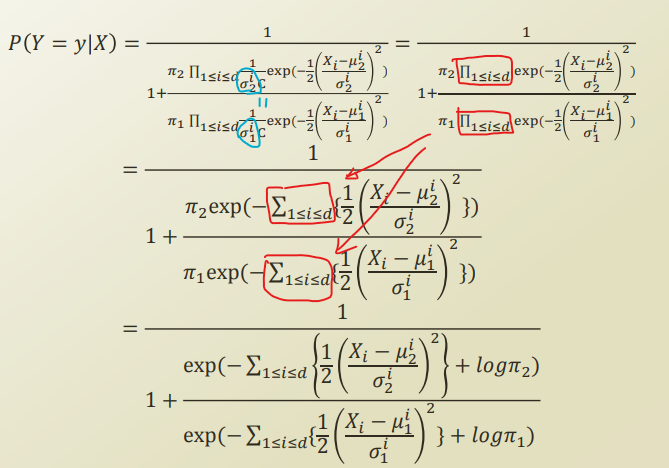
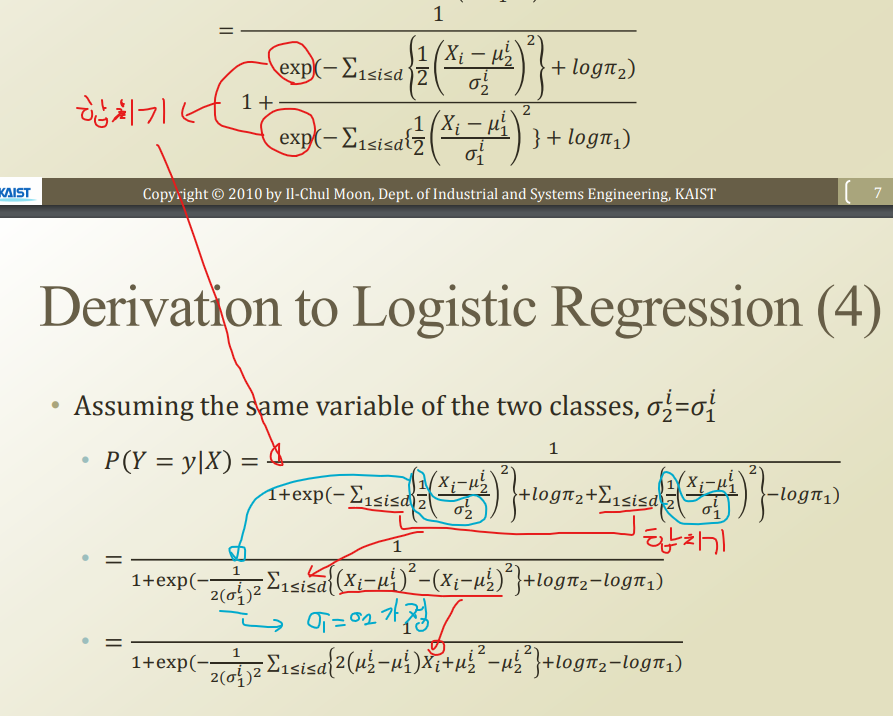
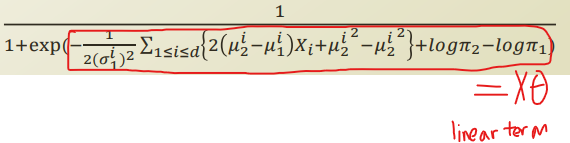
Naive bayes vs logistic regression
우리가 위와같이 식을 전개해서 naive bayes 와 logistic regression이 같아지게 하기 위해, 어떤 것들을 가정했는지 살펴보자.
- Naive byes assumption, same variance assumption between classes
-
gaussian distribution for P(X Y) likelihood - bernolli distribution for P(Y) prior
naive bayes 에서 필요한 parameter 개수를 계산해보자. 각 variance 계산과 prior 계산을 위해 4d + 1 개의 parameter가 필요하다.
logistic regression은 얼마나 paramter가 필요할까?
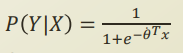
logistic function에 fitting 하기 위해, theta와 bias 를 정의해야한다. 따라서 d+1 개의 parameter가 필요한다.
그럼 두 방식중 어느것이 더 좋을까?
일단 정확도 측면에서는 보통 logistic regression이 더 좋다고 알려져있다. parameter 수도 더 적다.
하지만 naive bayes 는 MAP 처럼 priro 정보등을 우리가 컨트롤해서 넣을 수 있기 때문에 사람의 판단을 모델에 더 주입할 수 있다.
Generative-Discriminative Pair
다시 generative 와 dsicriminative 의 차이를 살펴보자.
generative model은 likelihood, prior, bayeisian, joint probability 등에 대한 modeling이 필요하다. full probabilisitc model for variables
discriminative model은 주로 conditional probability 을 modeling한다. 각 variable 들의 distributio을 직접 학습하지 않는다.
아래 Andrew Ng 교수님의 논문에서 각 장단점이 잘 설명되어있다고 하니 한번씩 읽어보자.
Pros and Cons [Ng & Jordan, 2002] • Logistic regression is less biased • Probably approximately correct learning: Naïve Bayes learns faster