last update datetime: Mar 07, 2020 9:02 PM

L2 regularization 은 미분 가능하므로, Gradient descent 에 쉽게 적용할 수 있다.
위 람다 값은 hyper parameter이다.
lambda 값을 높이면 regularization을 더 강하게 준다는 의미가 된다.
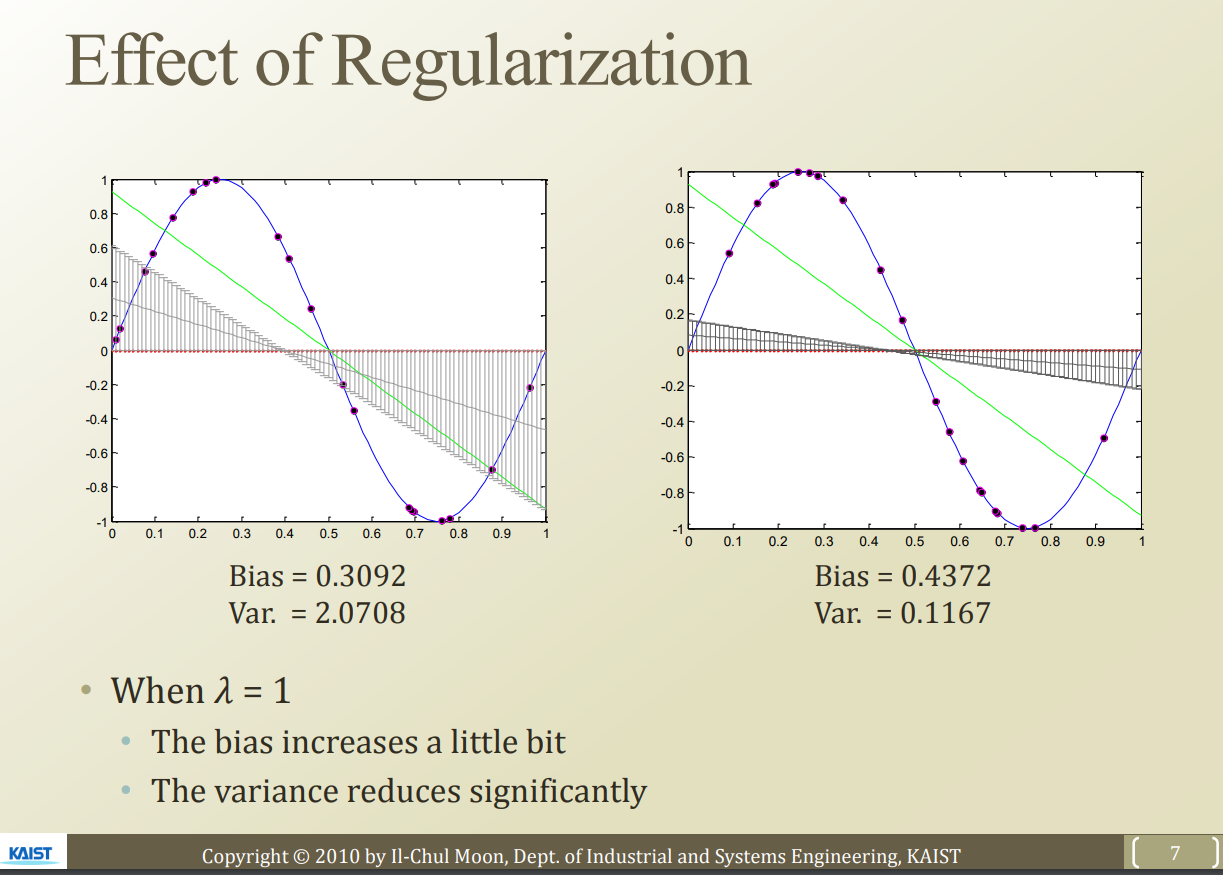
왼쪽은 이전에 사용헀던 sin 함수에 regularization을 적용하지 않은 상태이다.
오른쪽은 regularization을 적용한 상태이다. test data에 대한 variance error 가 확실히 줄은 것을 알 수 있다. 하지만, perfect fit을 할 수 없게 했으므로 bias 는 올라가는것을 알 수 있다.
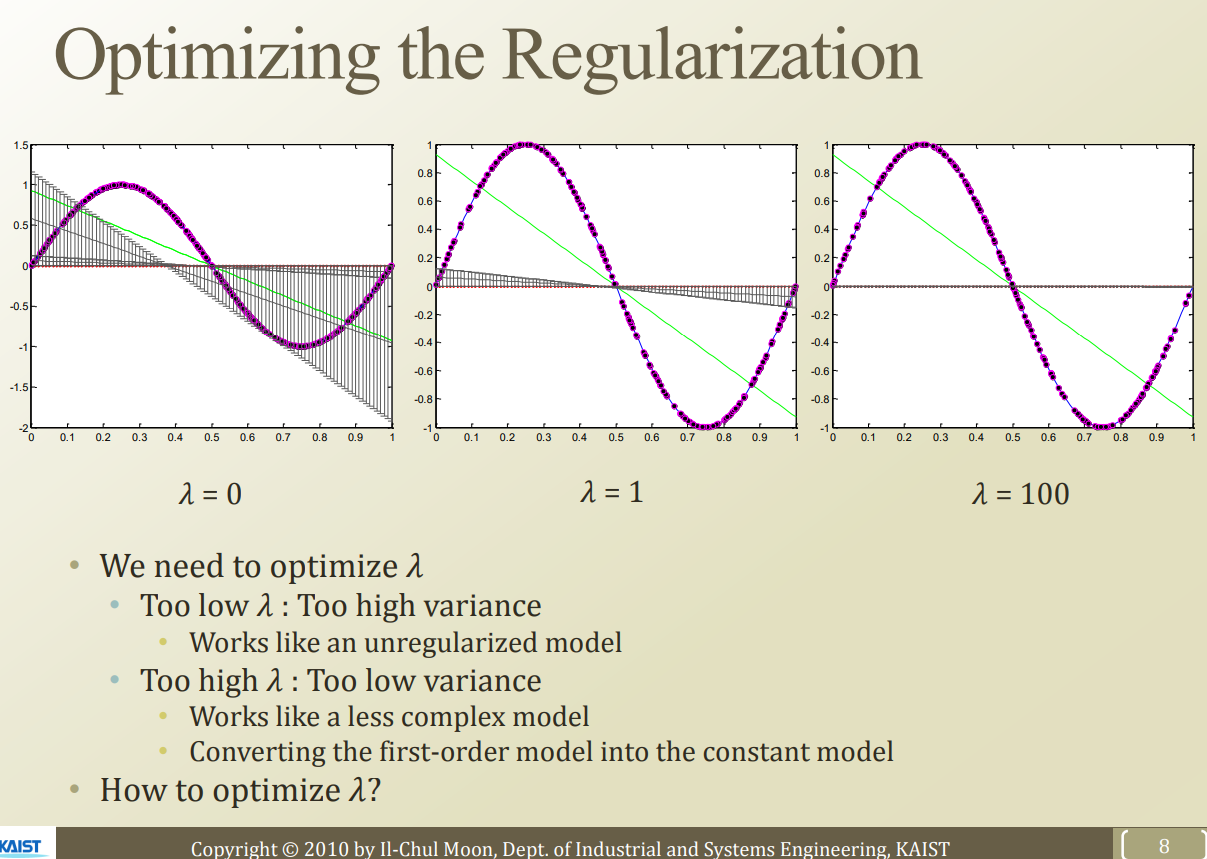
lambda 는 어떻게 최적화 해야할까?
lambda 값이 너무 낮으면 여전히 variacne error 가 높게 나올것이고, lambda 값이 너무 크면 모델의 complexity 를 낮추는것과 동일한 결과를 가져온다.
그 중간의 적절한 지점을 찾아야 한다.

logistic regression에도 동일하게 regularization term 을 추가하면 regularization이 된다.
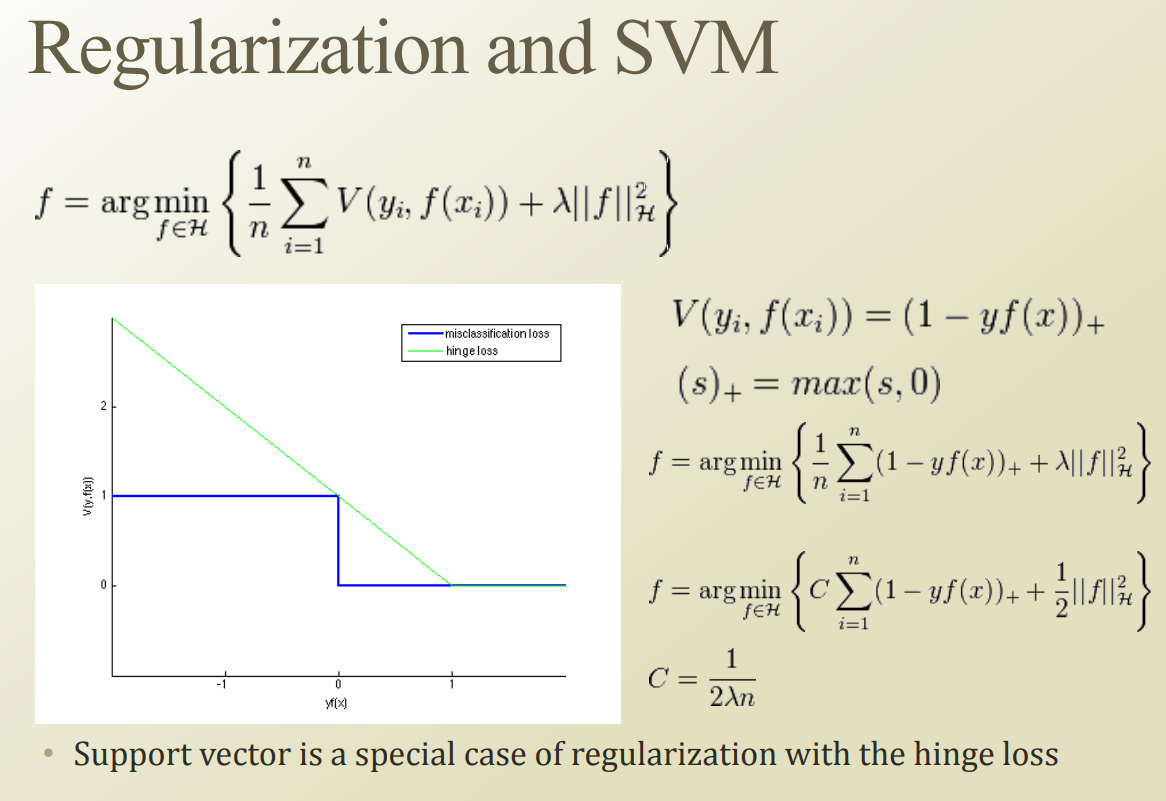
SVM 의 경우, 이미 soft margin 을 추가하면서 regularization이 추가된 상태이다. l1, l2 가 아ㅑ닌 hinge, zero one regularization이 적용된 형태.