
전체적인 learning process 에 대해 학습해보자.
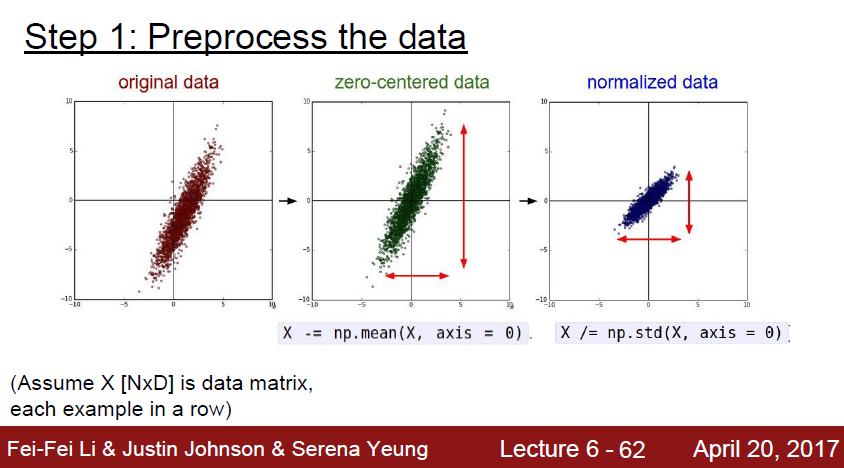
데이터를 학습하기전에, 머신이 데이터를 잘 학습하기 위해서 데이터를 잘 가공해서 넘겨줘야한다.
위에서도 나왔지만, zero-centered data 를 만들어줘야한다.
이 과정은 데이터를 평행이동시키면된다.
또한 데이터들의 분포를 normalization 해줄 필요가 있다.
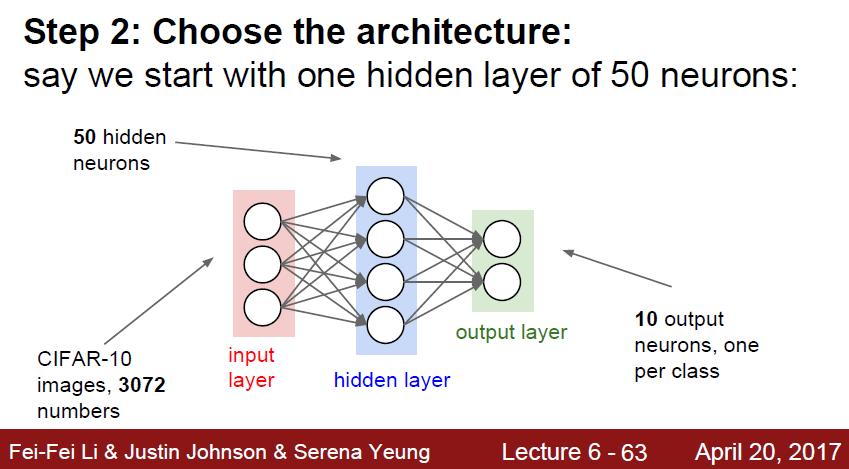
데이터를 잘 가공하였다면, 그 후에는 이 가공된 데이터를 학습할 모델을 선정해야한다.
Hidden layer 를 어떻게 구성할지, 어떤 layer 를 쌓을지, CNN을 쓸지 RNN 을쓸지 RCNN을 쓸지
Attention을 걸지 등등의 판단을 해야한다. 또한 layer 의 크기도 결정지어줘야한다.
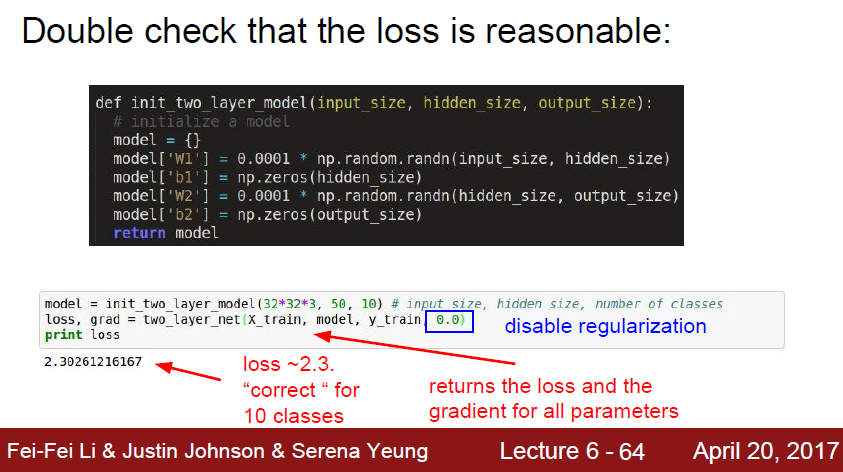
이렇게 구성한 model 로 loss 가 잘 나오는지 봐야한다.
이때 적용할것들은 얼마나 regularization을 할지, 이에 따라 loss 가 어느정도 나오는지 이다.
regularization 의 수치를 높였을때 loss도 같이 올라가는지도 확인해줘야한다.

처음 룬현을 할때는 모든 데이터를 넣지 않고, 작은 데이터 셋을 먼저 넣어서 학습시킨다.
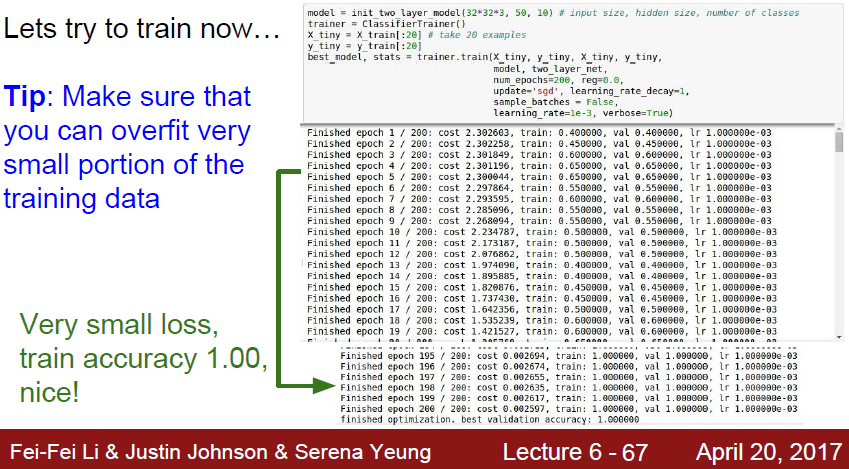
데이터 수가 작기 때문에 Overfit이 발생한다. 여기서 Overfit이 나온것은 다행입니다.
모델이 잘 data 를 따라갈 수 있다는 반증이기 때문입니다.
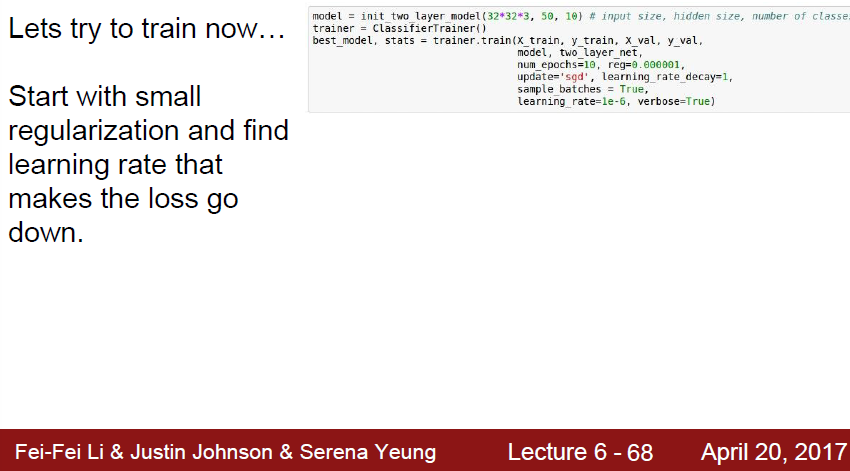
이제 model 밖에서 건드려줄 수 있는 parameter 들인 learning rate 와 regularization rate 을 건드려봅시다.

learning rate 가 1e-6일때, 학습이 잘 되지 않습니다.
너무 lr 이 낮아서 생기는 문제입니다.
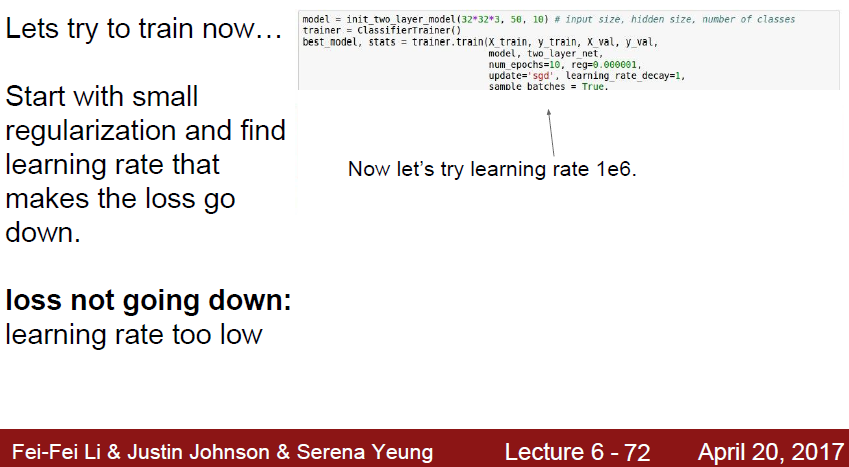
이번에는 learning rate을 1e6을 잡고 학습시켜봅시다

cost 가 nan 으로 튕겨나가버립니다.
처음 머신러닝을 배우면서, 2차함수에서 튕겨서 학습이 튕겨져 나가버리는 그 원리와 똑같습니다.
learning rate 가 너무 높으면 발생하는 문제입니다.

이번에는 3e-3 을 넣어봅시다. 여전이 cost 가 inf 로 튀는것을 볼 수 있습니다.
이렇게 learning rate 을 얼마나 가져야하는지를 대략적으로 알 수 있습니다.