
이제 여러가지 hyperparameter 들을 optimization하는 방법을 학습해봅시다.

적은 ecpoch 으로 넓은 범위의 hyperparameter 들을 실험해보고,
그 후에 긴 learning time 에 상세한 hyperparameter 들을 찾아간다.

예제로 보면,
10**uniform(-5,5)가 넓은 범위를 뜻하게된다, 또한 log space 에서 optimization 하는것이 좋다고한다.
결과를 보면, learning rate 가 e-04, reg 가 e-01에서 학습이 잘 된것을 볼 수 있습니다.
이제 이 결과를 가지고 좁은 범위에서 학습해봅시다.

range 를 조정하고 다시 학습을 해보았더니
이번에는 48% 보다 높은 53%의 정확도를 가지는 범위가 나왔습니다.
하지만 이 53%지점이 무조건 정답이 아닙니다.
-3 미만을 아직 측정을 해보지 않았다는점이 걸립니다.
따라서 optimization을 할때는 -3.-6 에서 -3.-4 로 줄이는게 아닌
-2.5.-4 로 줄여서 아래 범위까지 채크해주는게 좋습니다.
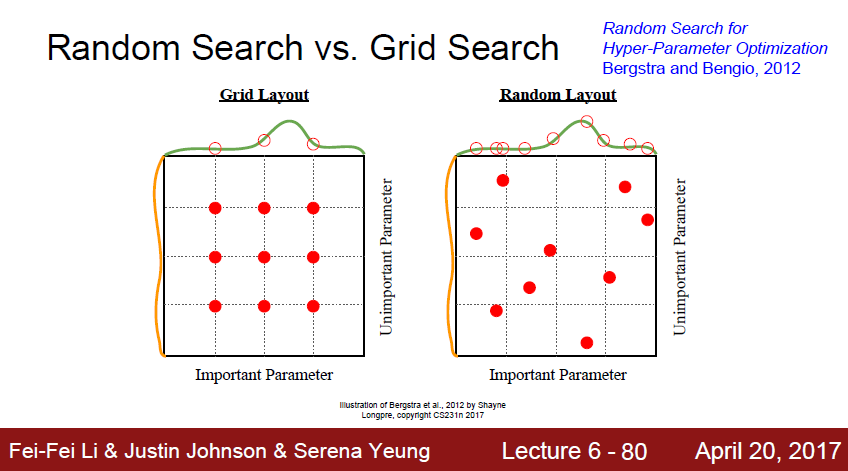
이렇게 값을 찾는데는 2가지 방법이있다.
Grid search, random search가 있다.
random search가 더 좋다.
그 이유는 grid search는 절대 찾지 못하는 영역이 발생하기 때문이다.
랜덤으로 서치할경우가 오히려 더 빨리 optimization 영역에 도달할 확률이 높다.

이렇게 하이퍼 파라미터를 찾는 과정은 DJ 가 클럽에서 노래를 조절하는것과 비슷하다고 한다.
정답은 없고 계속 위와 같이 통계적인 방법으로 찾아가야한다.

실제는 이렇게 많은 시도를 통해서 최적의 값을 찾는다고한다.
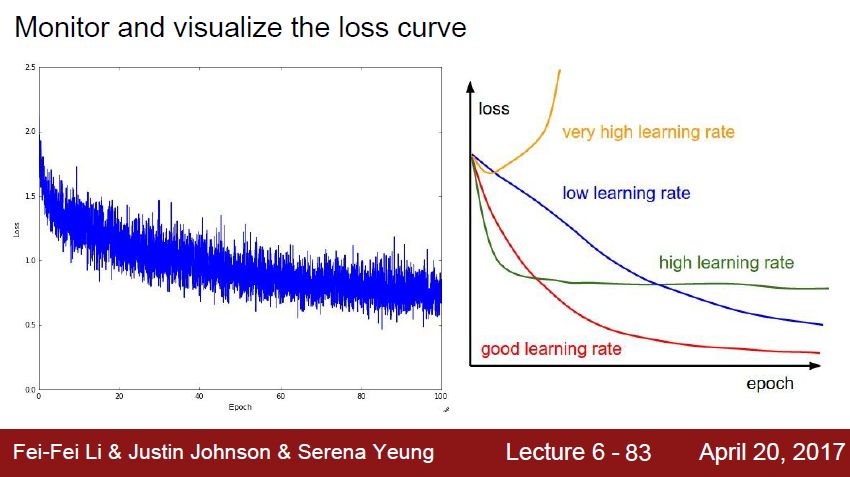
Loss curve 를 모니터링할때도 방법이 있다.
오른쪽 그래프에서 빨강색 그래프일 때를 찾아야한다.
learning rate 가 너무 높아도, 너무 낮아도 안된다.
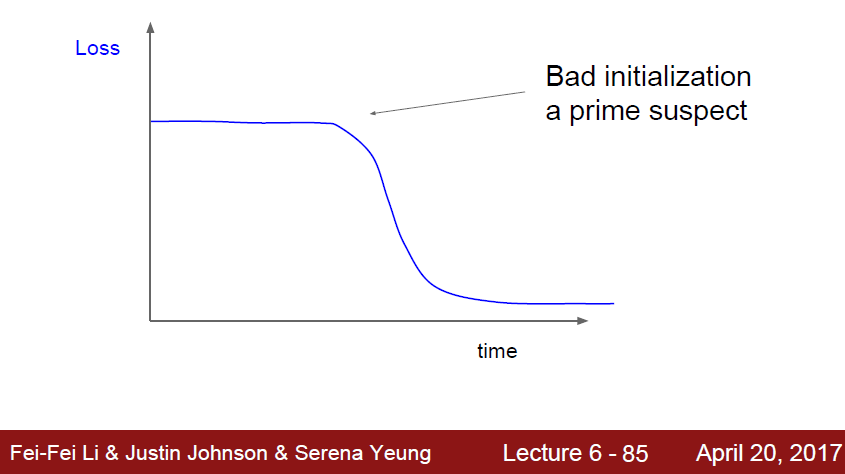
가끔가다 이러한 모양의 loss graph 를 볼 수도있따.
초기에 나쁜 initilization에 의해 학습을 못하다 적절한 값을 찾아서 그 시점부터 학습이 시작된것이다.
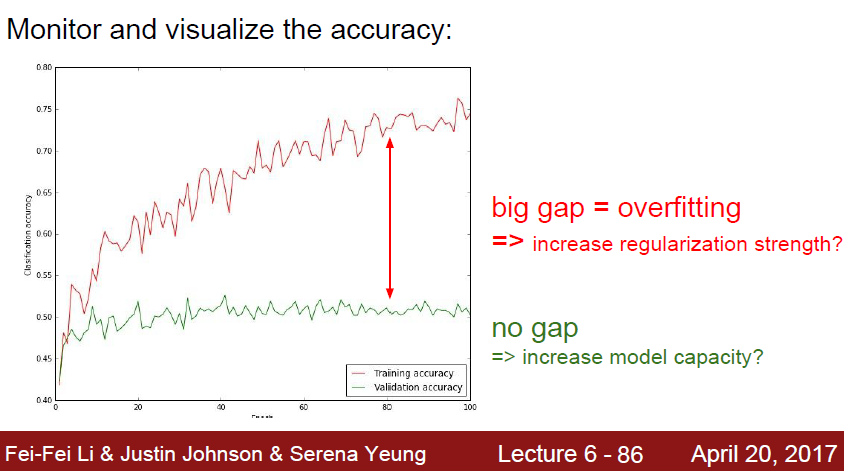
실제 데이터와 훈련 데이터 상에서 위와같이 갭이 크다면, 이 모델은 overfitting 된것이다.