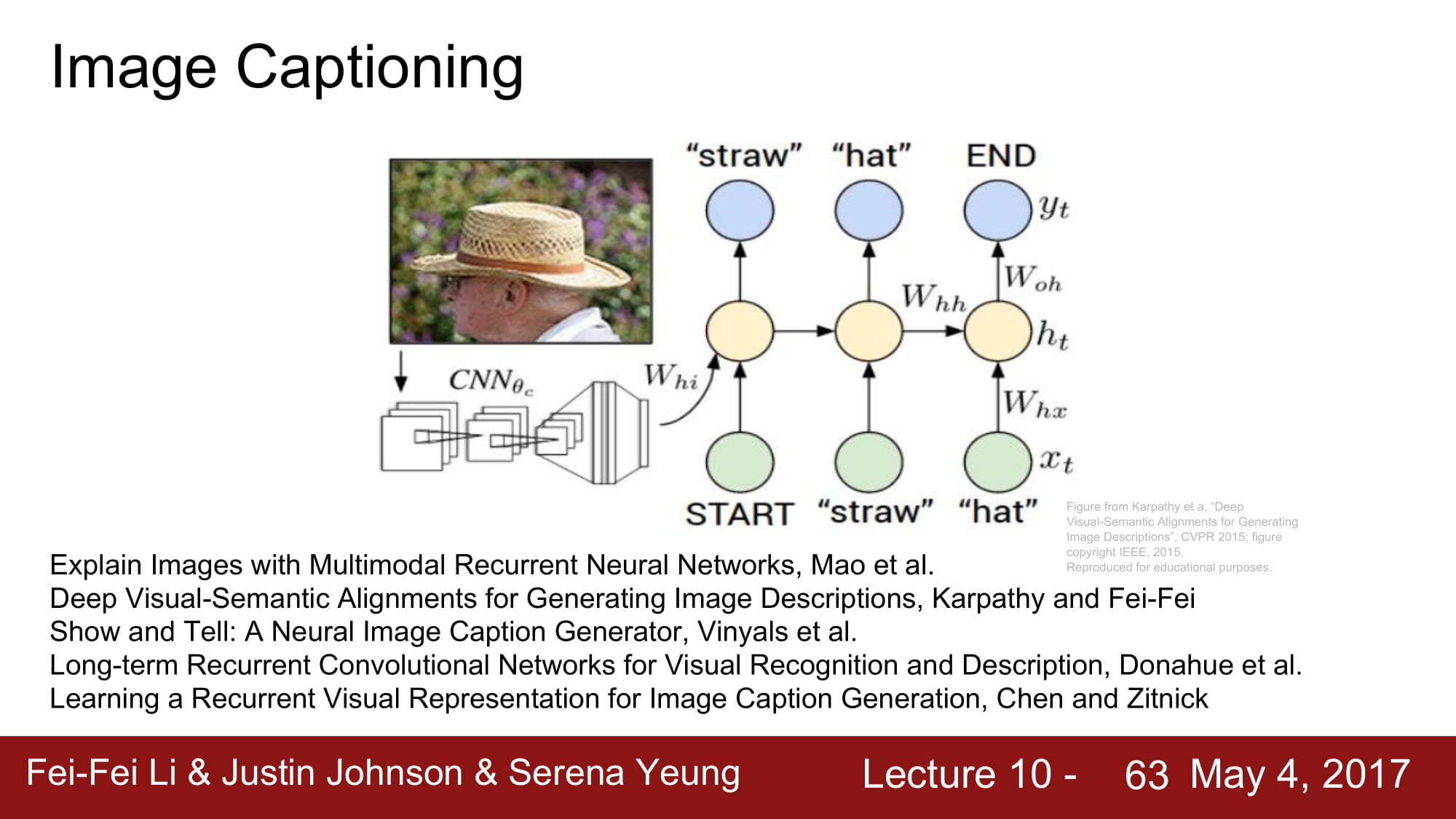
Image captioning 은 대표적인 CNN 과 RNN 을 혼용한 모델이다.
이미지를 CNN 으로 feature extraction 하여 특정 vector 로 만들고, 그것을 기반으로 그 이미지에 달린 caption을 학습하게된다.

Test image 를 넣고 conv layer 를 타면서 feature 를 뽑게된다.
마지막 softmax 를 통해 분류하지 않고, fc layer 를 통해서 나온 벡터를 출력하게된다.
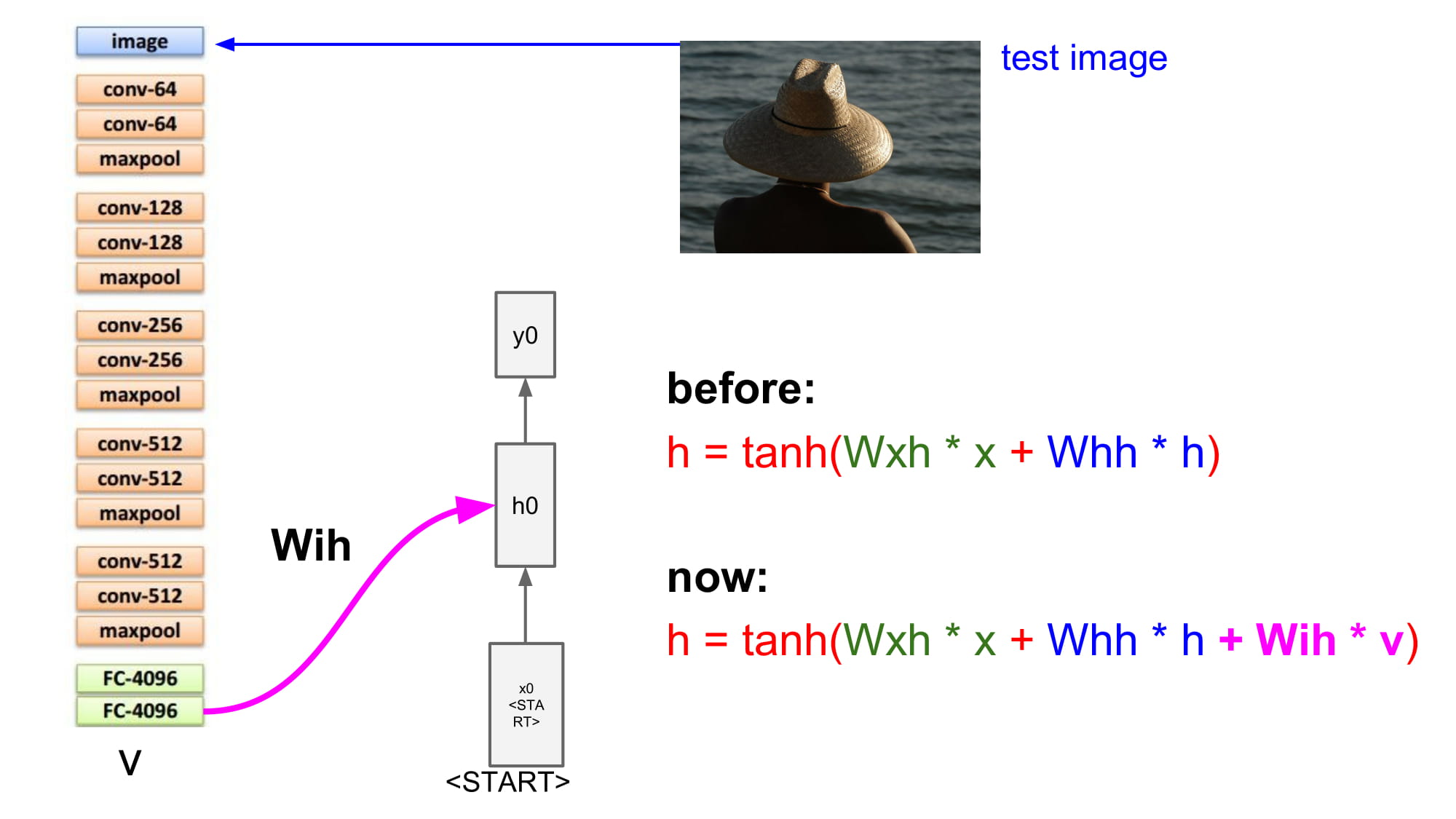
이 경우에는 fc layer 의 vector 가 위의 v 가 된다. 계산해야하는것이 3개가 된것이다.(이전 스탭 hidden state, 이번 스탭 input, image vectoer V)
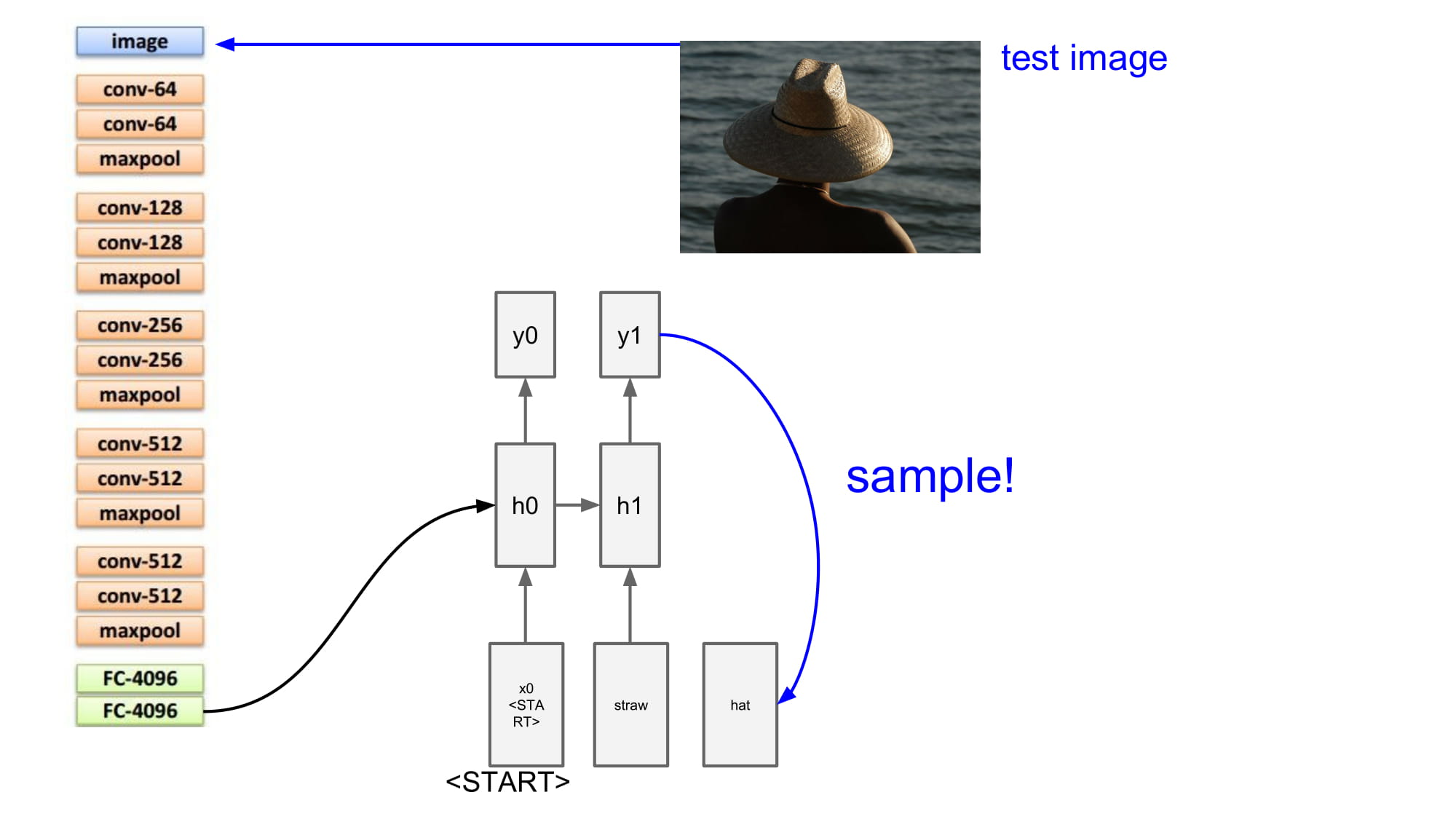
그럼 처음 input 은 무엇일까? 문장의 시작을 알리는 <start> 토큰 을 넣게된다.
이때 image vector 는 모든 Rnn cell 에 동일하게 들어가게된다.
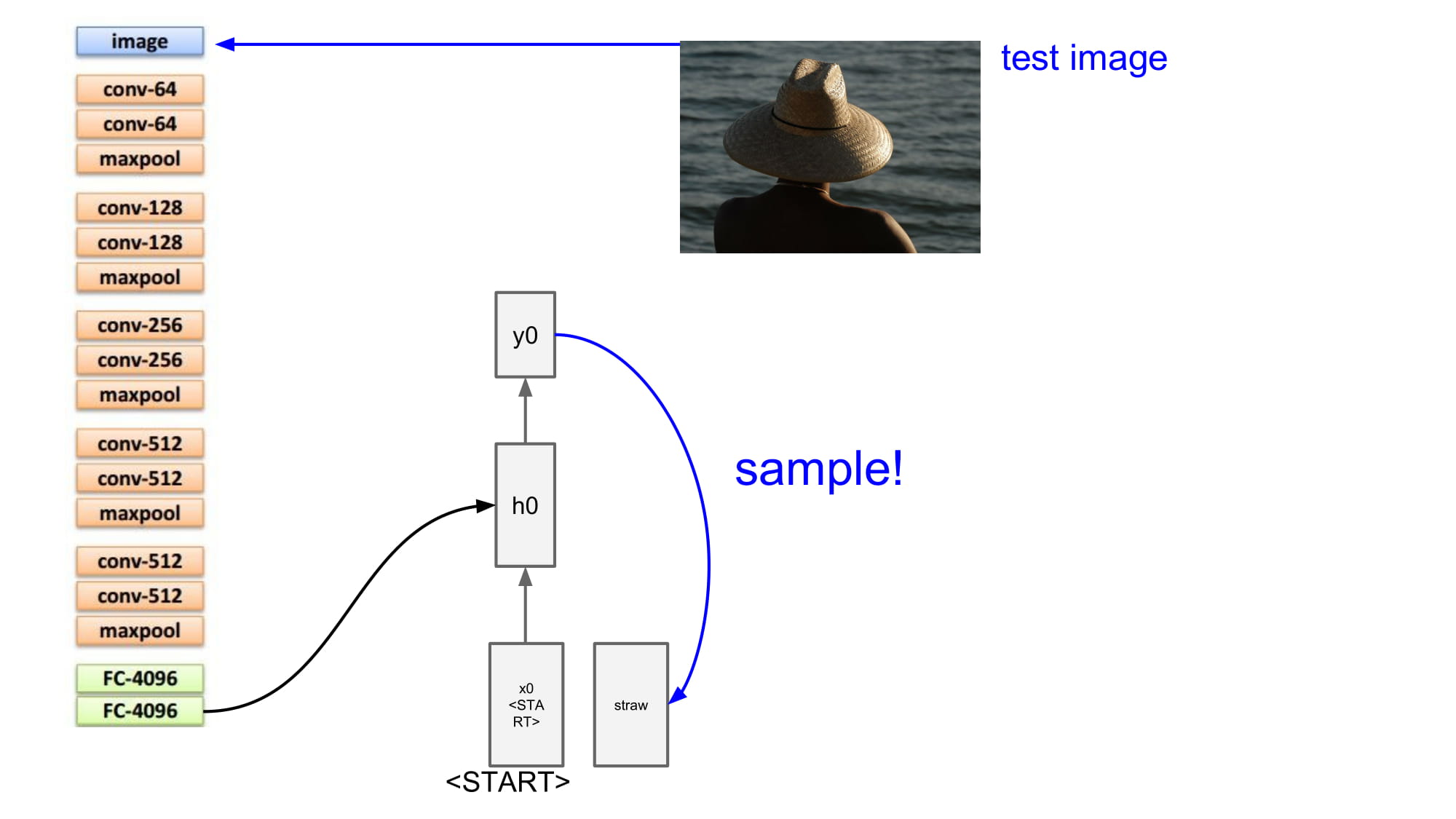
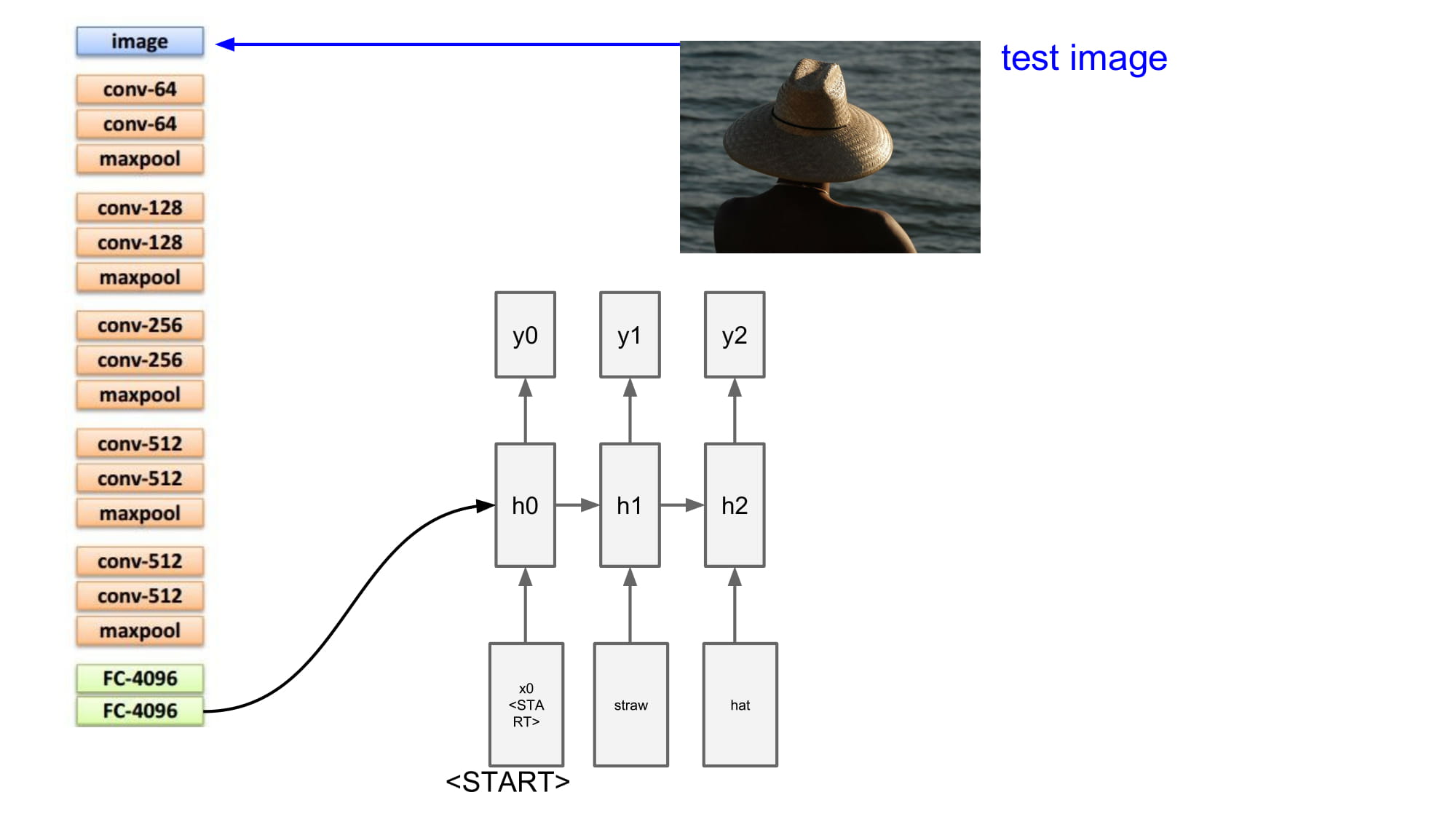
결과로 나온 단어를 다음 단계의 input 으로 사용하게된다.
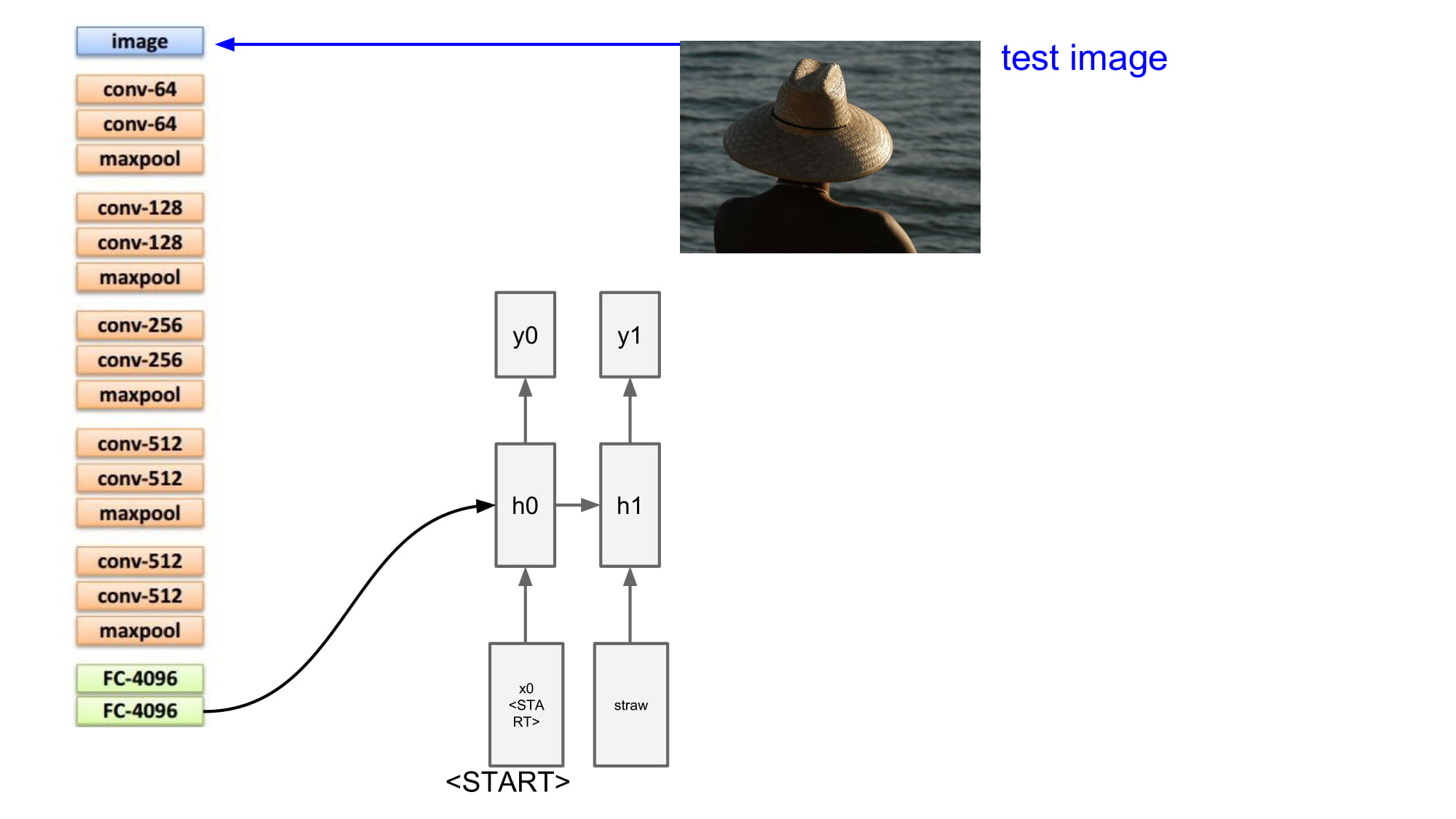
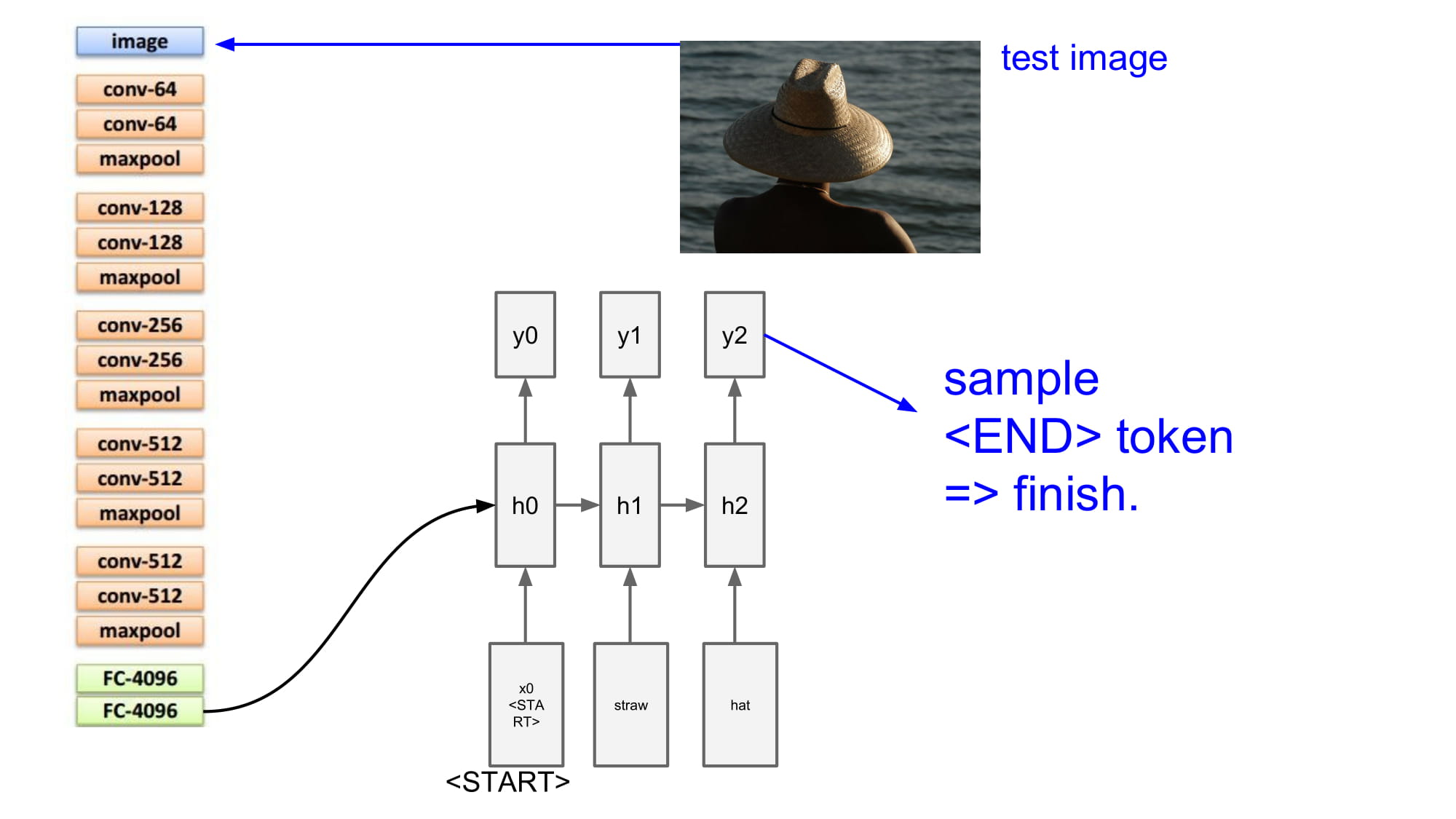
이렇게 반복하다가, 마지막에 <END> 토큰을 넣어서 문장이 끝났다고 알려준다.

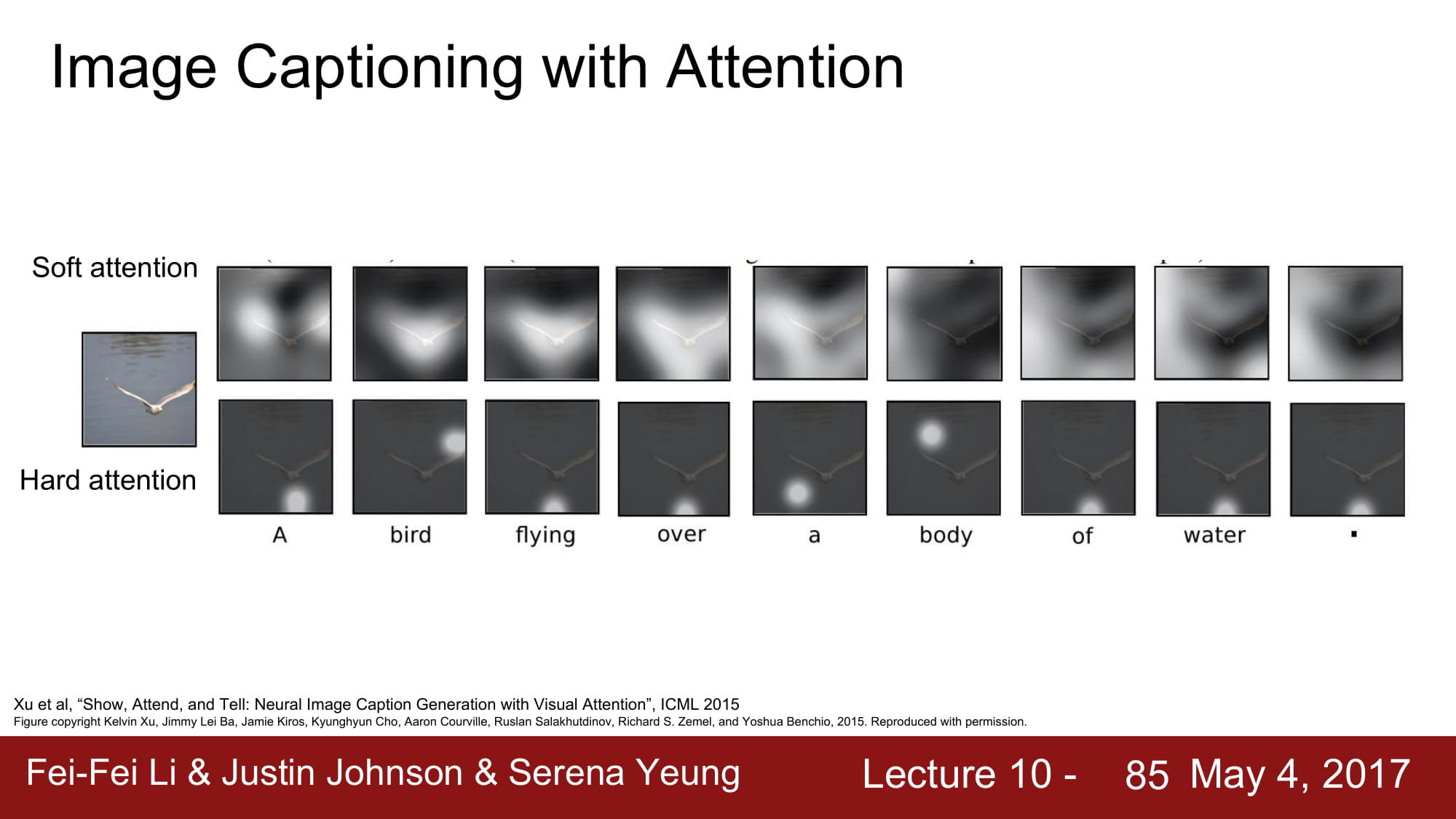
좋은 예시들이다. 잘되는것 처럼 보인다.

하지만 데이터에 없던 caption 을 써야 하는 상황이라면, 정확도가 낮아지기 시작한다.

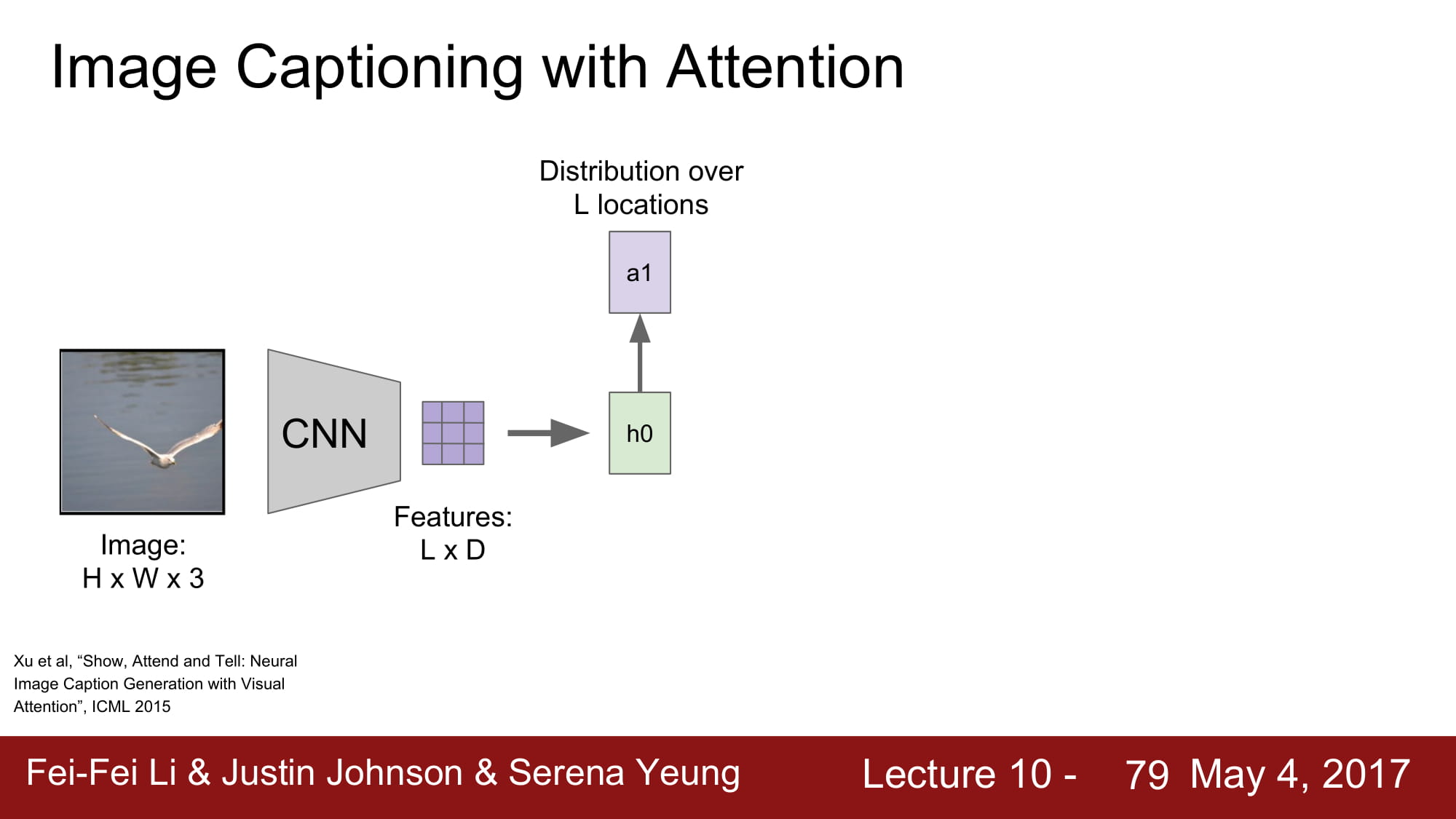
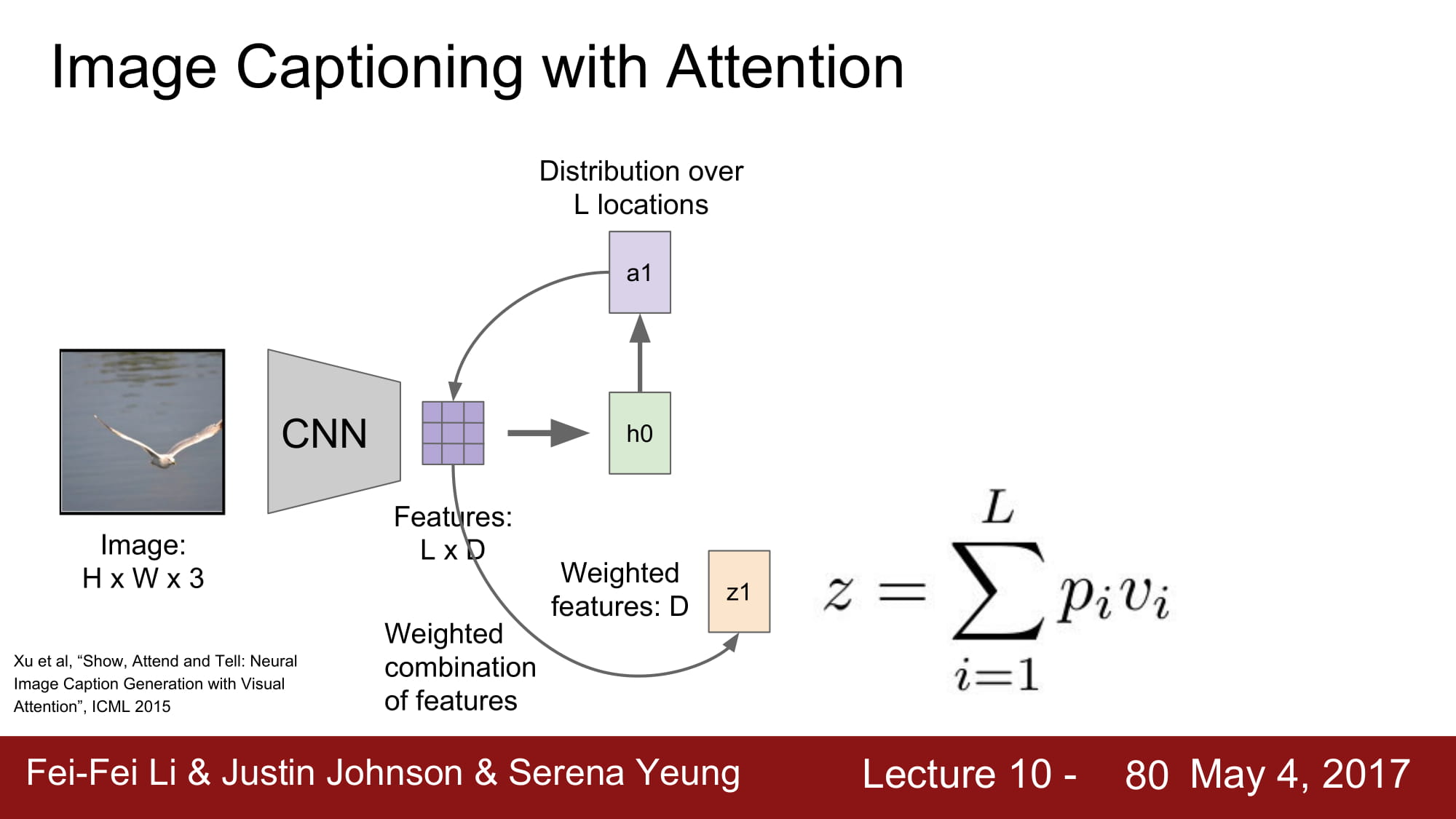
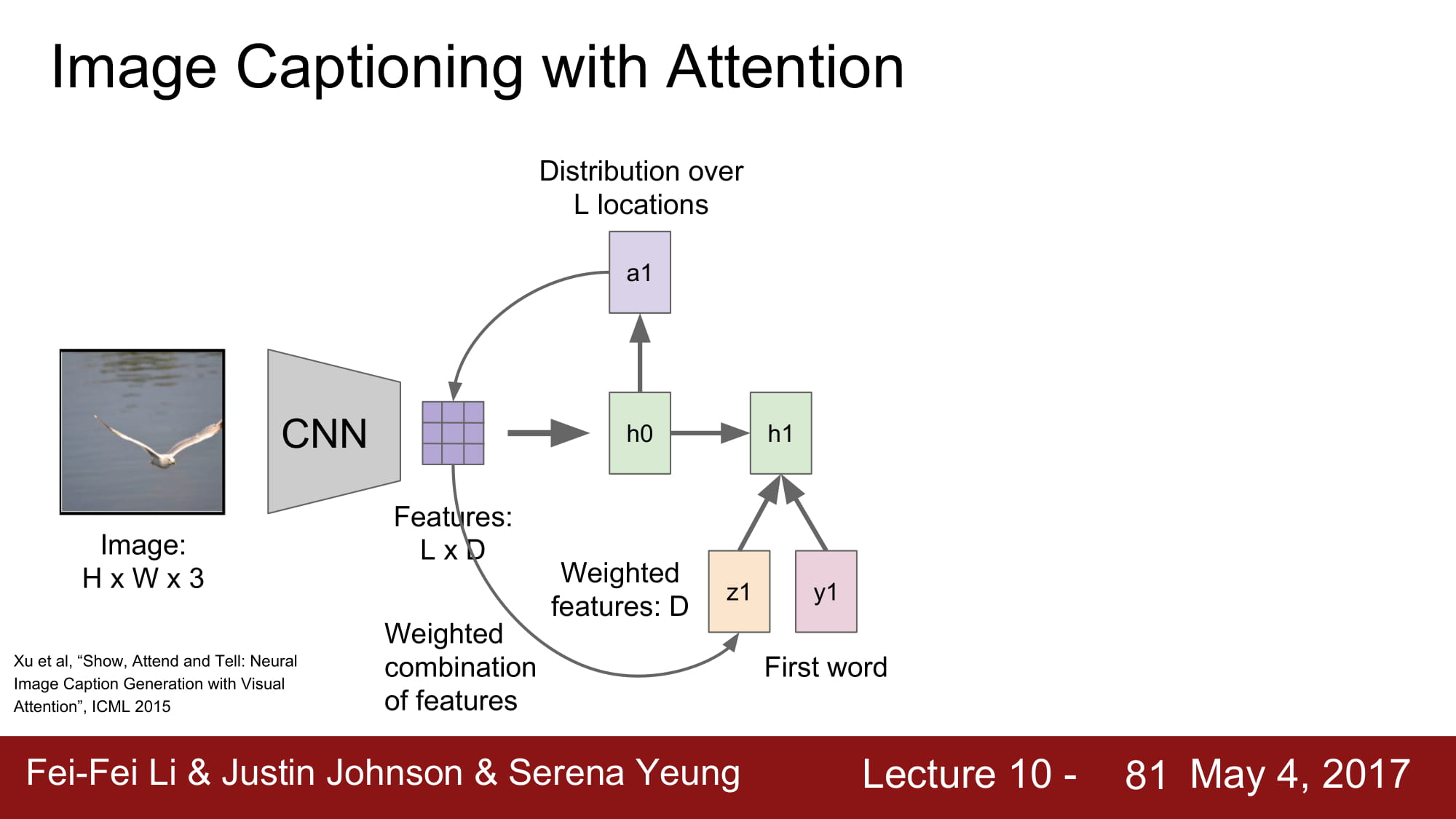
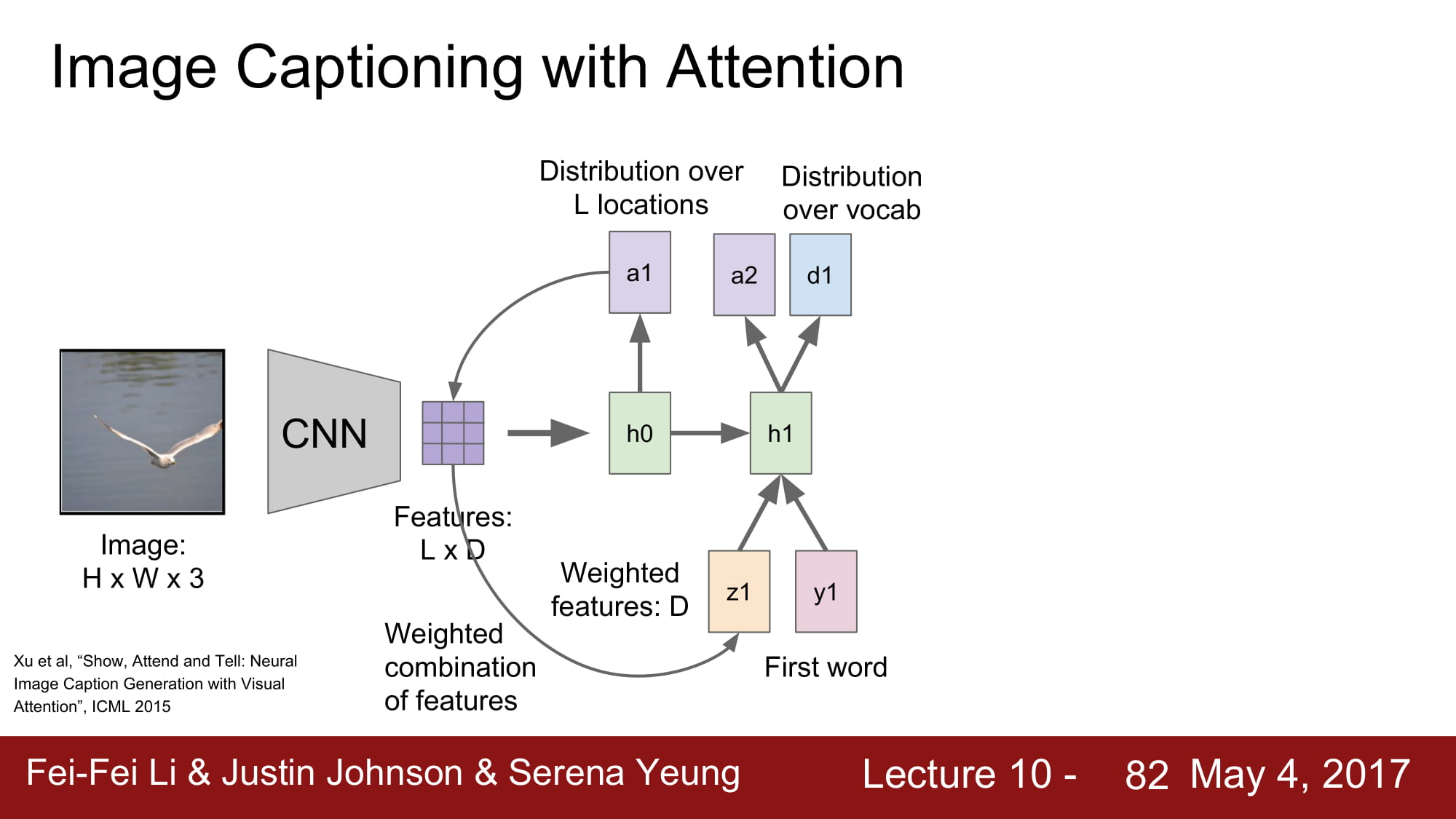
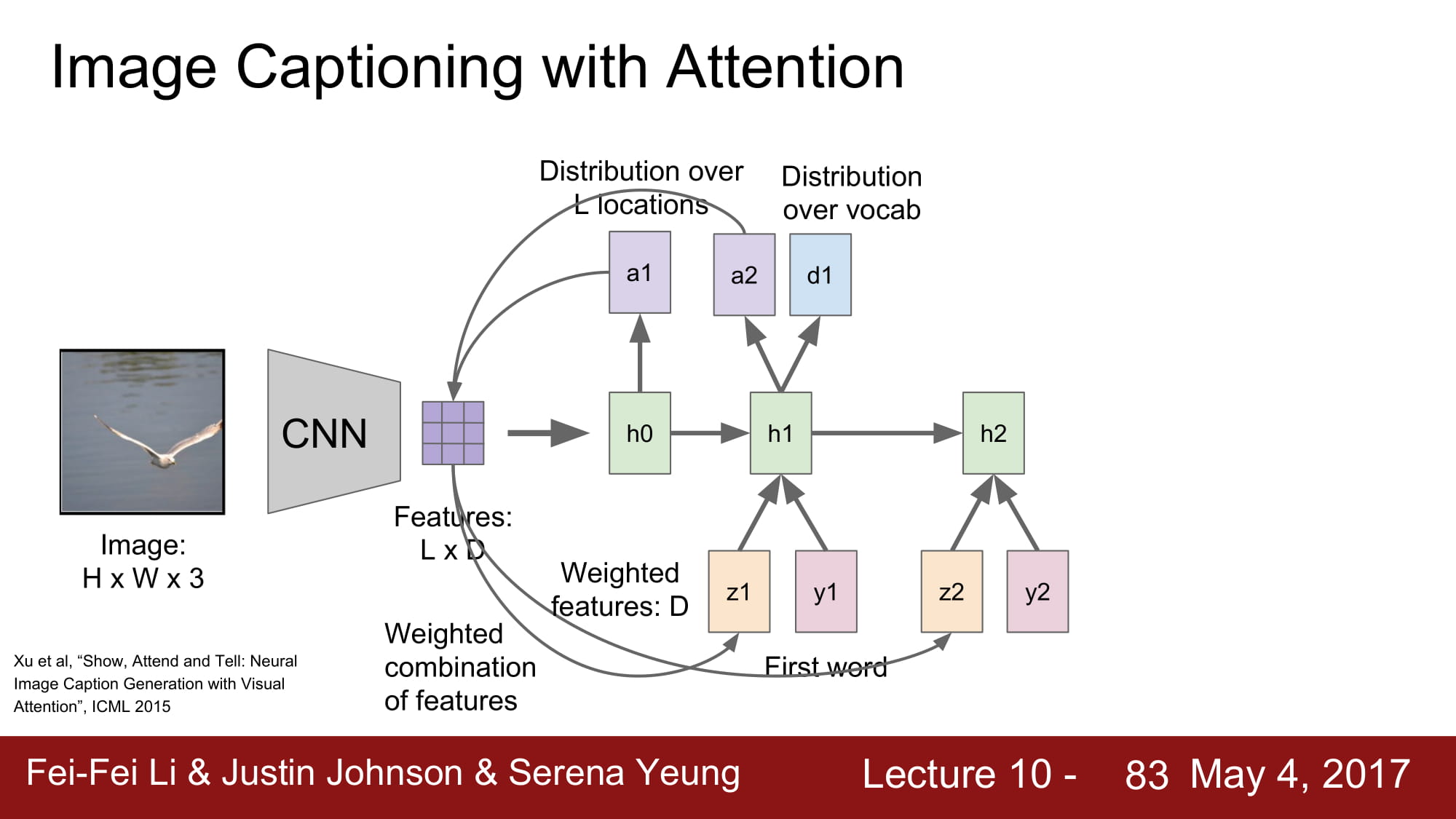
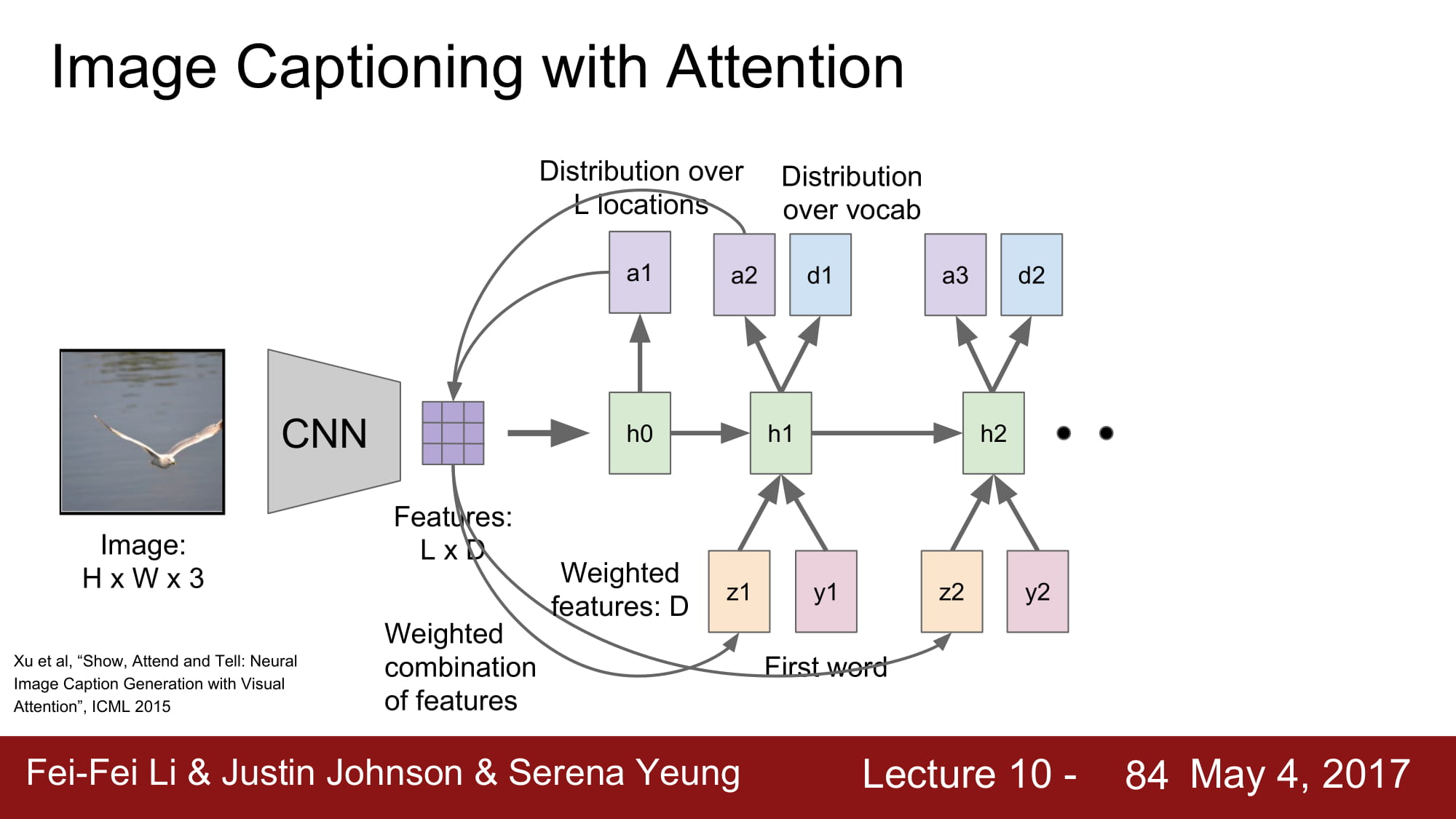
여기서 더 발전한 방법이 바로 Attension 기법이다.
Attension 이란 특정 caption 을 지정할때 image 에서 특정 location 에 집중한다 라는 뜻으로 쓰인다.
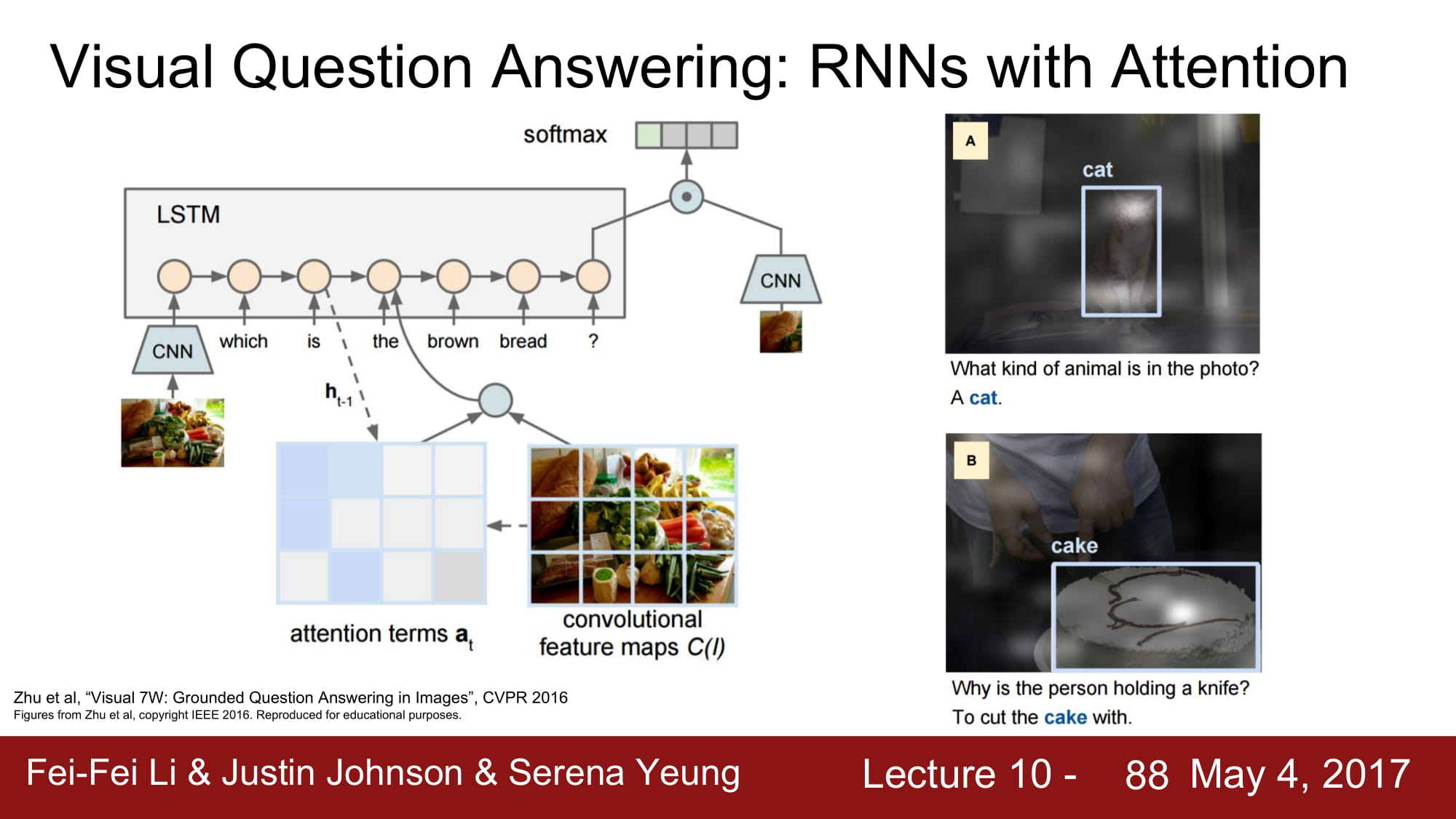
근데.. 강의에서도 깊게 알려주지 않고 나도 이해를 못해서 밑에는 슬라이드만 놓고 설명은 나중에 Attension 에 대해 다시 학습해서 따로 올리겠습니다..
다음주는 ResNet 과 Attension 에 대해 공부해봐야겠군요 어렵다 어려워 ㅠㅠ..
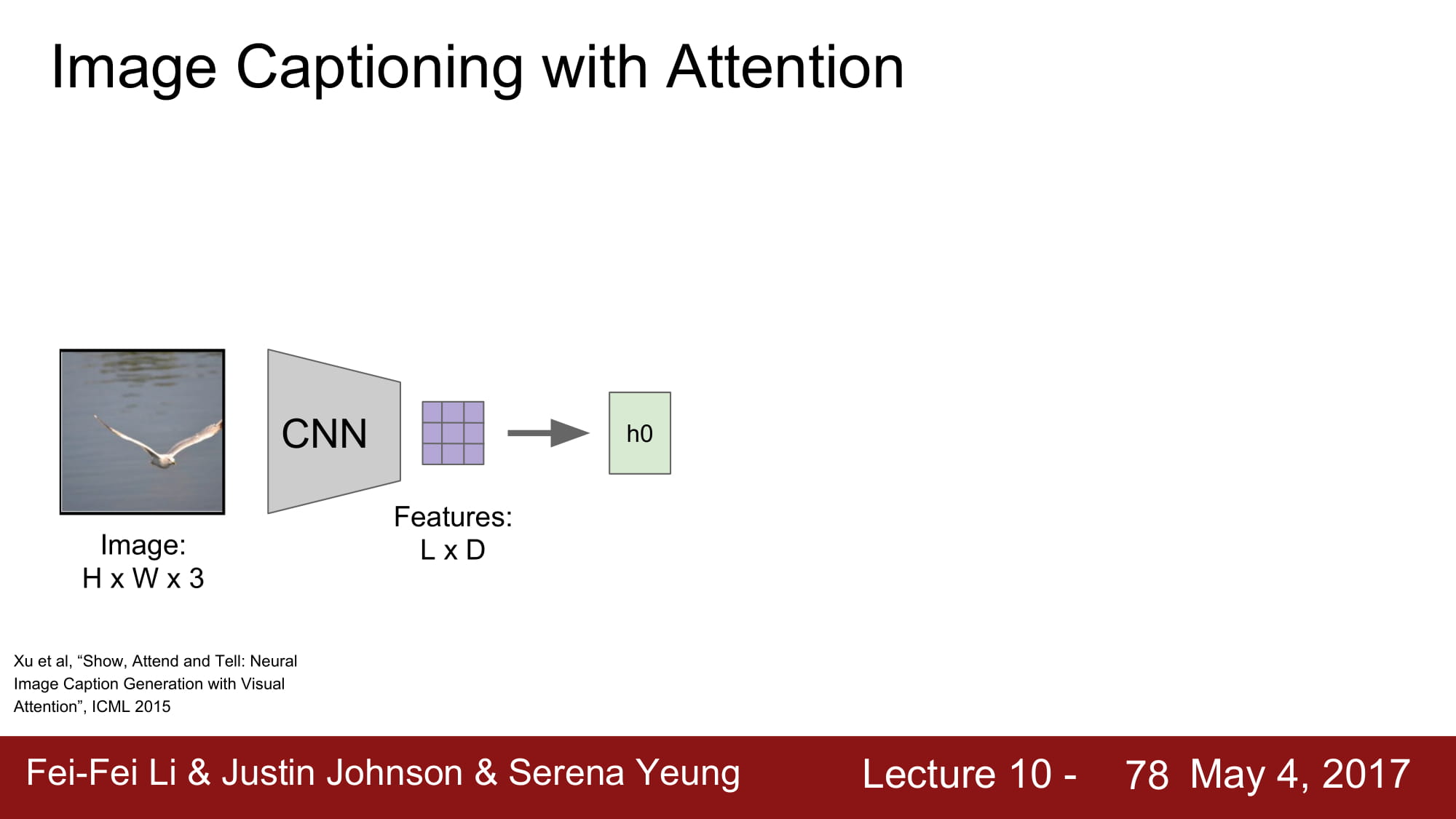
아쉽게도 이번 강의에서 attension 을 깊게 가르쳐주지는 않는다.
image 에서 CNN 을 통해 공간 정보가 깨지지 않은 데이터를 만들게 된다.