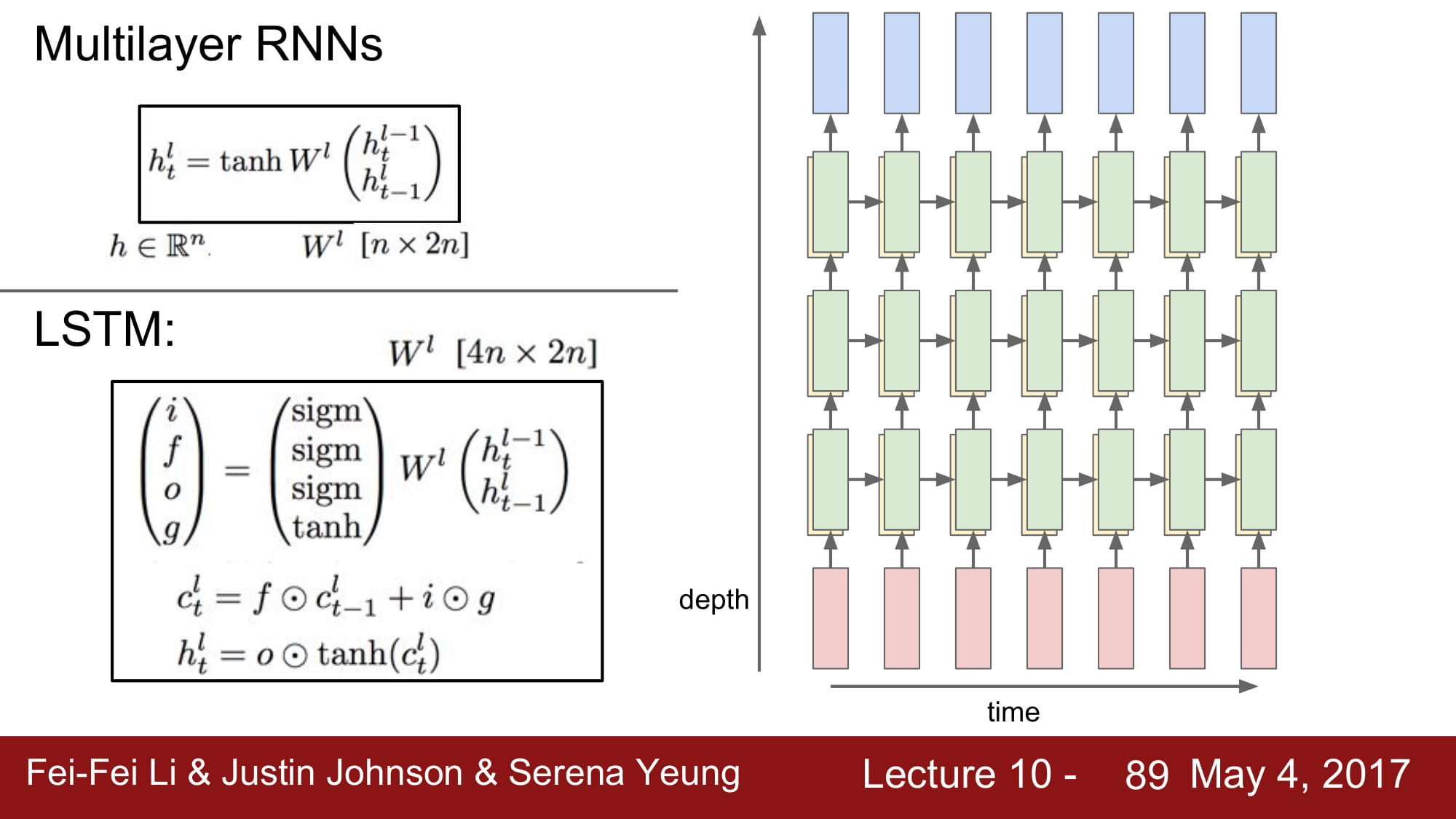
RNN 의 back prop 과 LSTM 에 대해 알아봅시다.
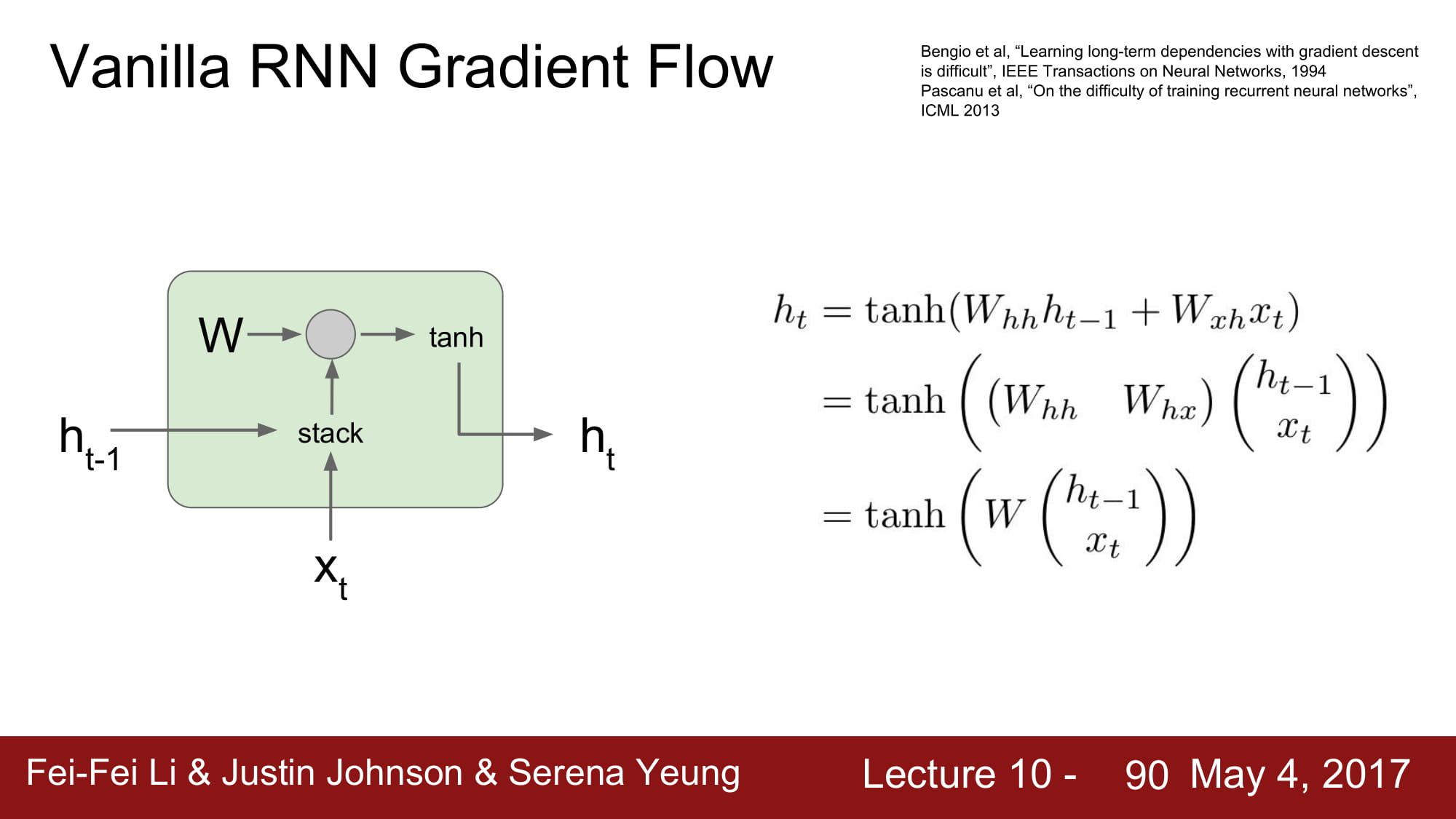
Vanilla Rnn 의 수식은 다음과 같이 Matmul 로 나타낼 수 있습니다.
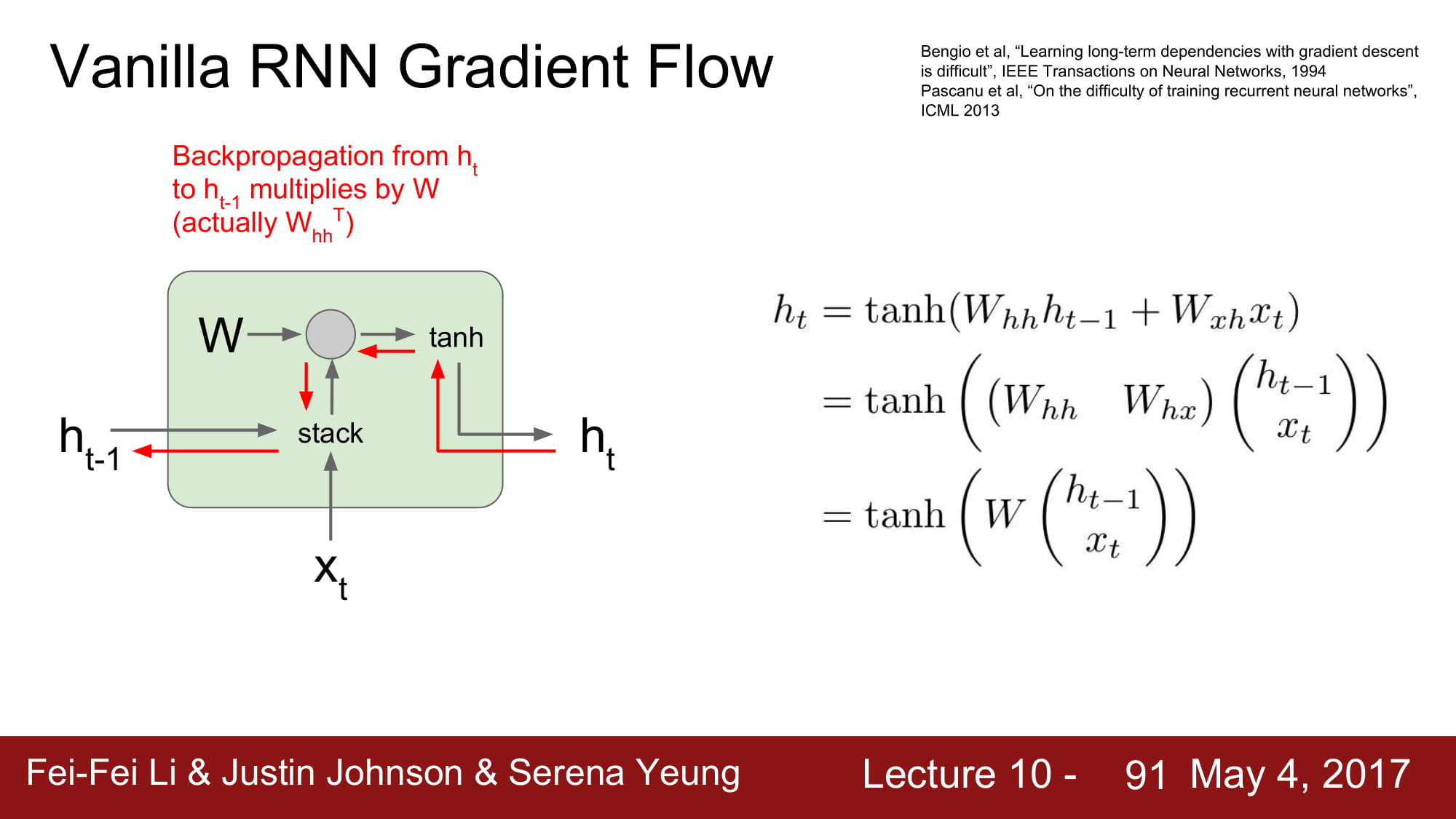
back prop 의 경로를 따라가보면, 결국 matrix multiplication 을 지나가야 하는데
이는 해당 matrix 의 transpose를 곱하게 됩니다.
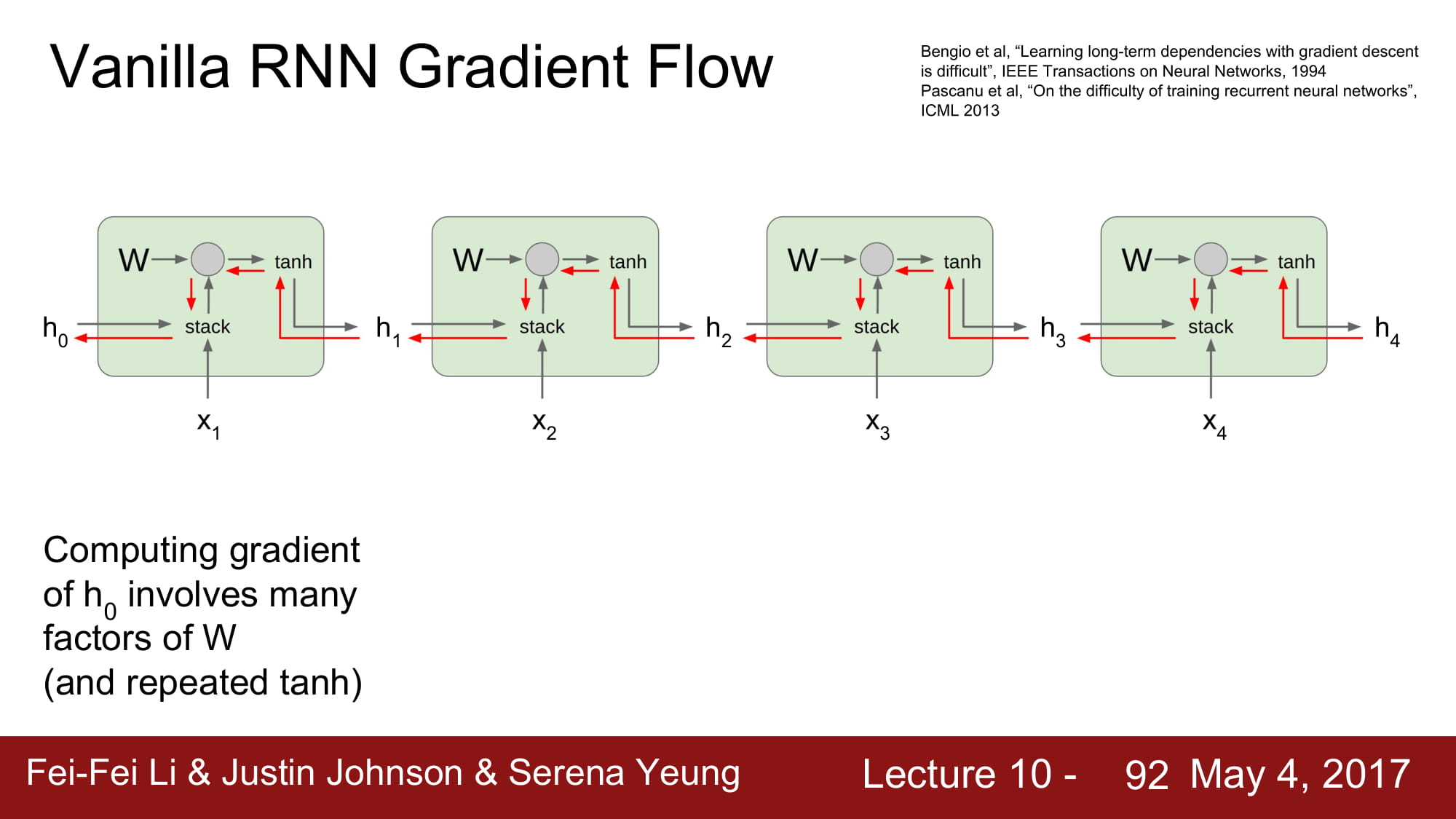
그럼 Vanilla Rnn Cell 을 지나갈때마다 W_transpose Matrix 를 계속 곱하게됩니다.
마지막 h0 의 gradient 를 계산하기 위해서는 수많은 W 를 곱했어야합니다.
이는 너무 비효율적이고, gradient vanishing 과 exploding 을 불러옵니다.
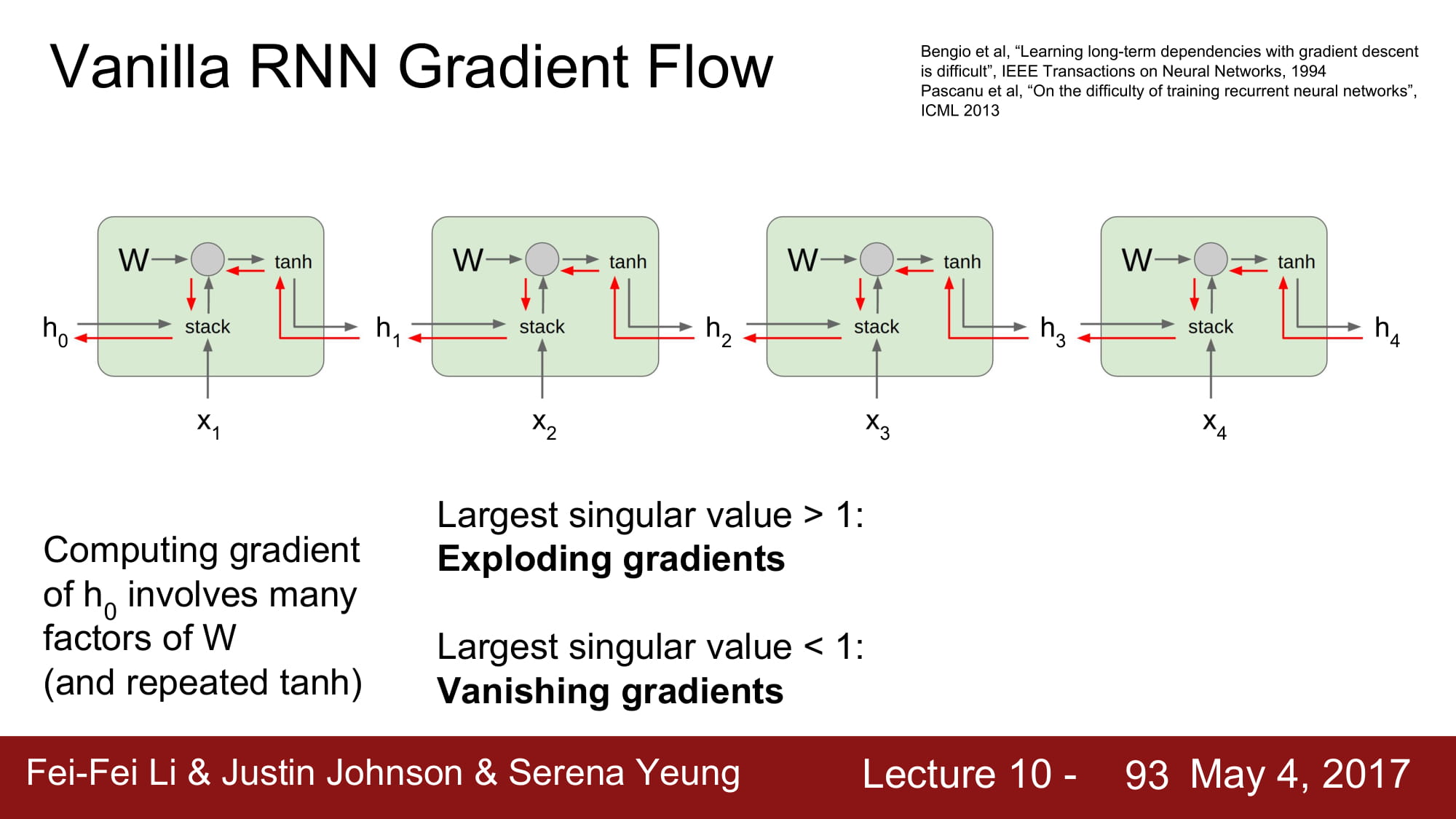
matrix 의 최대값이 1보다 크다면 exploding 을, 1보다 작다면 vanishing 효과를 가져오게 됩니다.
이렇게되면 깊게 학습하지 못하게 되죠.
Vanilla RNN이 Long input 을 학습하지 못하는게 바로 여기서 나옵니다.
항상 그랬듯이, Gradient가 끝까지 도달하지 못하기 때문이죠.
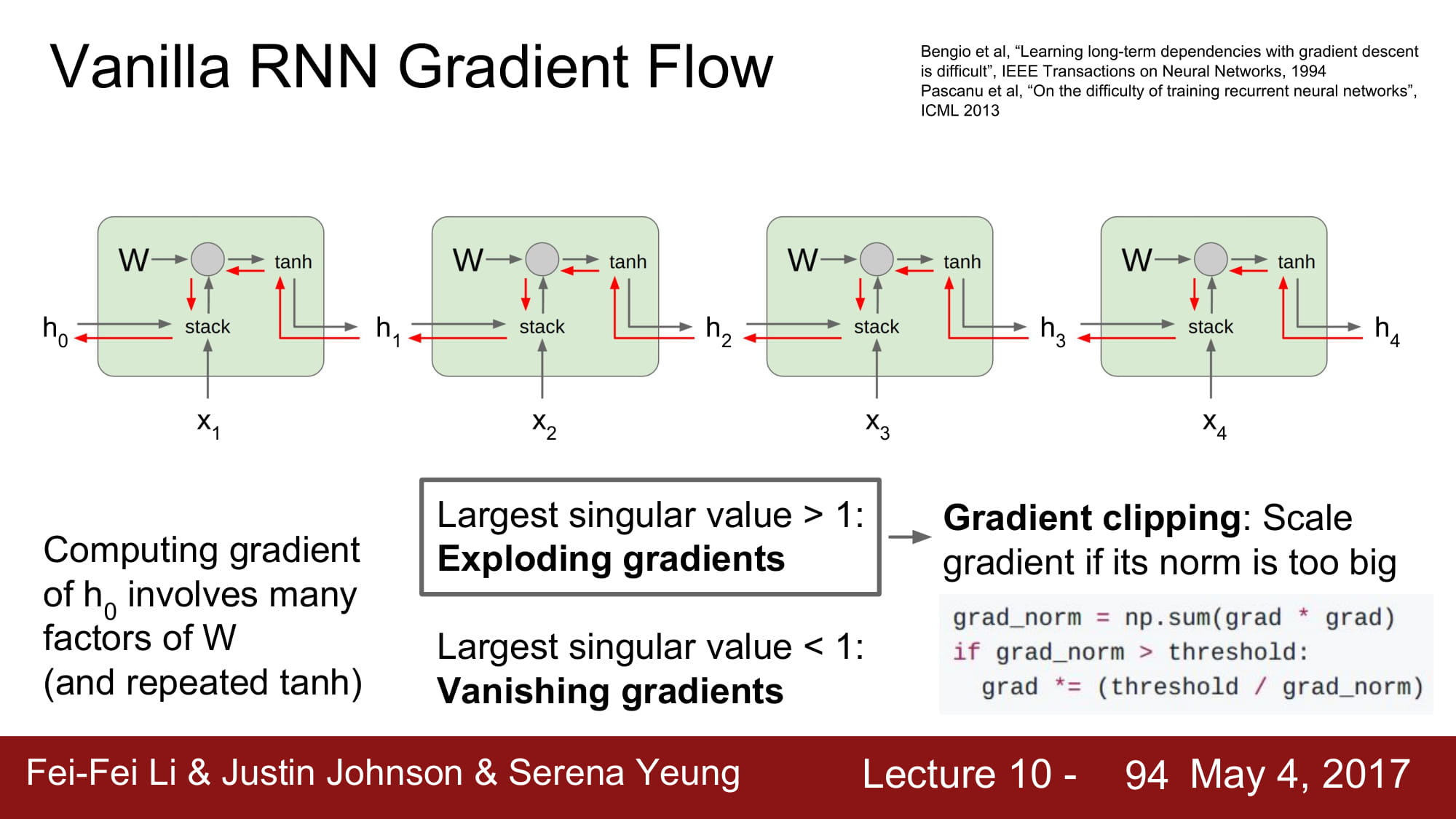
Exploding 은 threshold 를 정해서 gradient 값을 제한하는 ugly 한 방식으로 어느정도 제어할 수 있습니다.
하지만 vanishing 은 정말 답이 없죠…
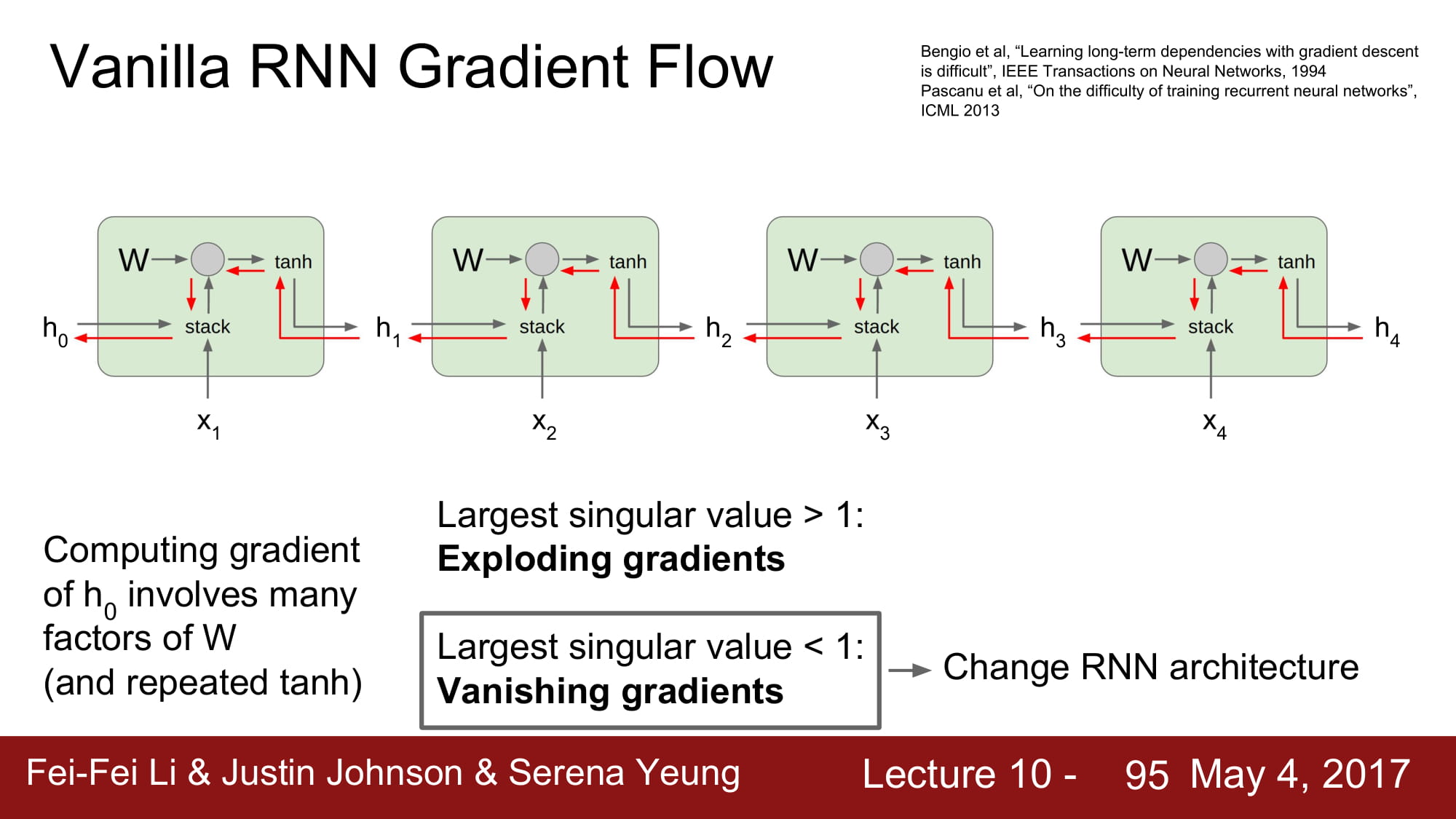
결국 어쩔수 없이 RNN architecture 를 변경해야합니다.
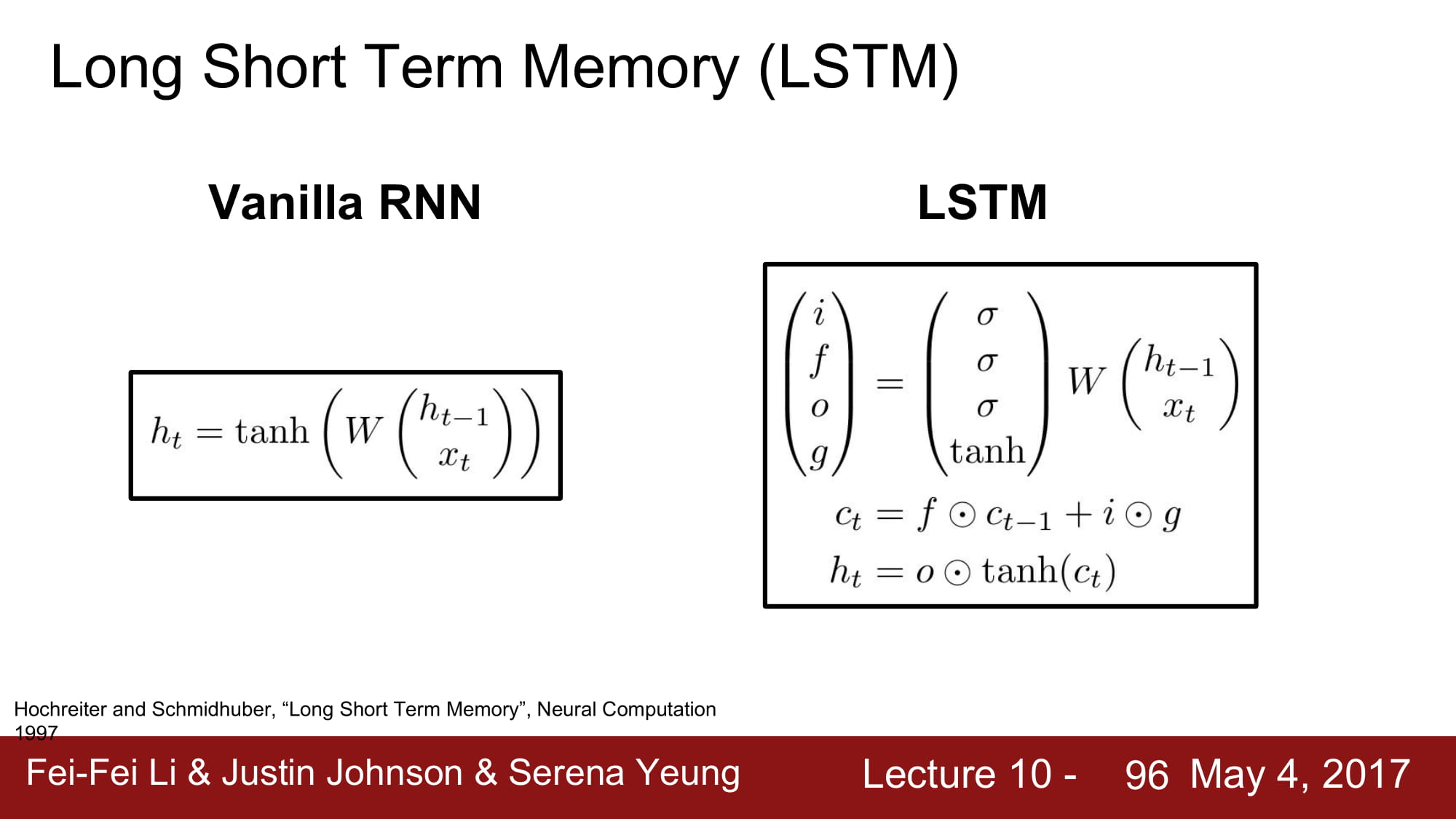
그래서 나온게 바로 LSTM 입니다.
LSTM 은 Long short term memory 라고 합니다.
장기 의존성 문제를 해결하기 위해 만들어진 architecture 입니다.
LSTM 은 Vanilla RNN 의 hidden state 계산 결과를 도출하기 전에
- input gate
- forget gate
- gate gate ?
- output gate
라고 불리는 gate 로 값을 계산합니다.
이를통해 Cell state 를 업데이트하고, Cellstate 로 다음 cell 의 hidden state 를 계산합니다.
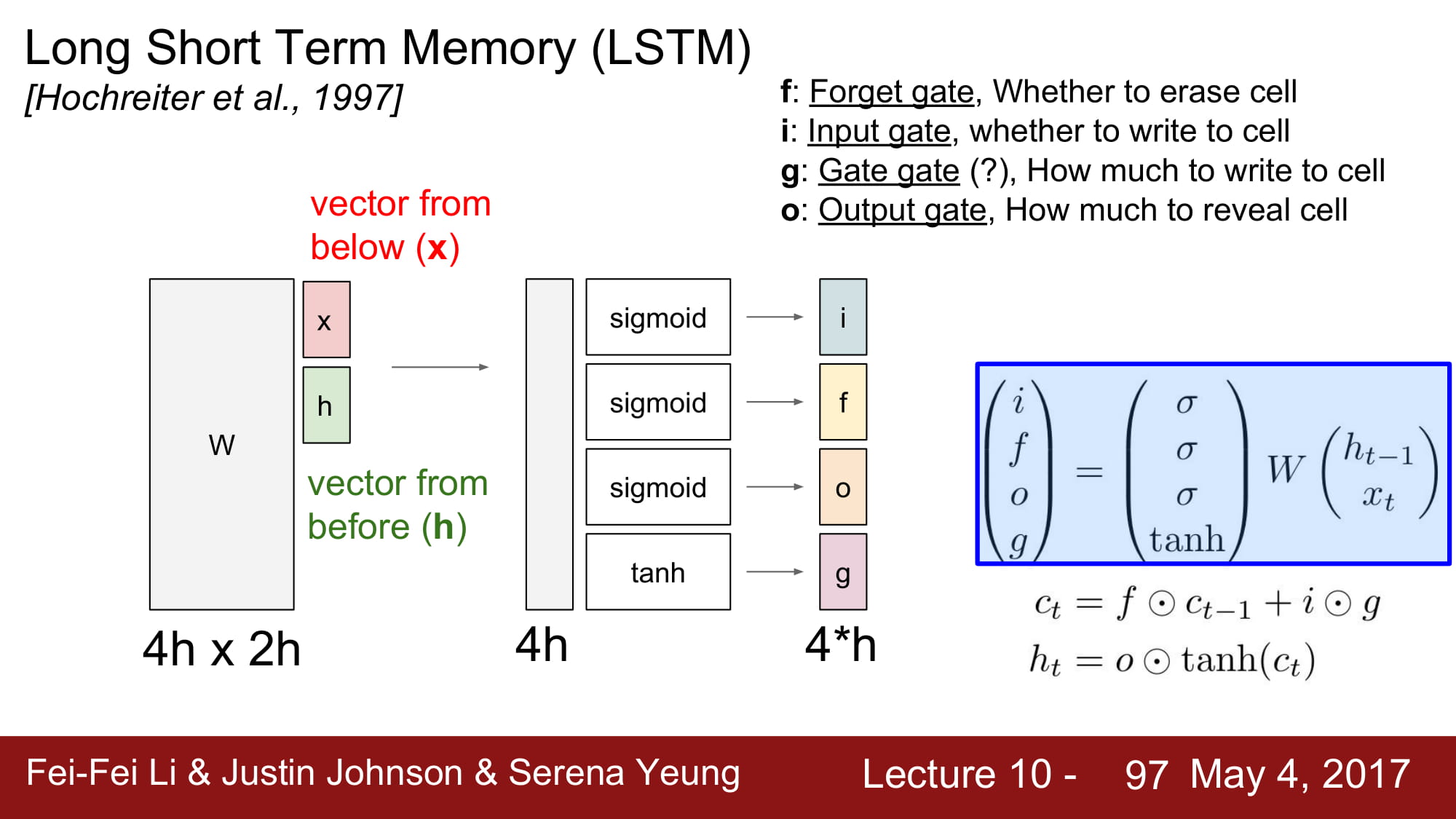
통칭 ifog 로 불리는 gate 들은 각각 sigmoid, sigmoid, sigmoid, tanh 를 걸친 결과를 가지고 있습니다.
각각 역활은
- input gate : gate gate 에서 나온 값을 얼마나 사용할것인가에 대한 0-1 사이 값. gate gate 와 pointwise 로 곱해짐
- forget gate : 이전 cell state 을 얼마나 ‘잊을 것인가’ 이다. pointwise multiplication 으로 이전 cell state 와 연산되며, 0에 가까울수록 ‘데이터를 잊고’ 1에 가까울수록 ‘데이터를 보존한다’
- output gate : 최종적으로 hidden state 를 구하기 위해 cell state 에서 얼마만큼을 사용할것인지 정하는 단계
- gate gate ? : Vanilla RNN 에서 만들어진 hidden state 와 동일한 값. 이제 이 값을 input gate 를 사용하여 얼마나 사용할것인지 결정함.
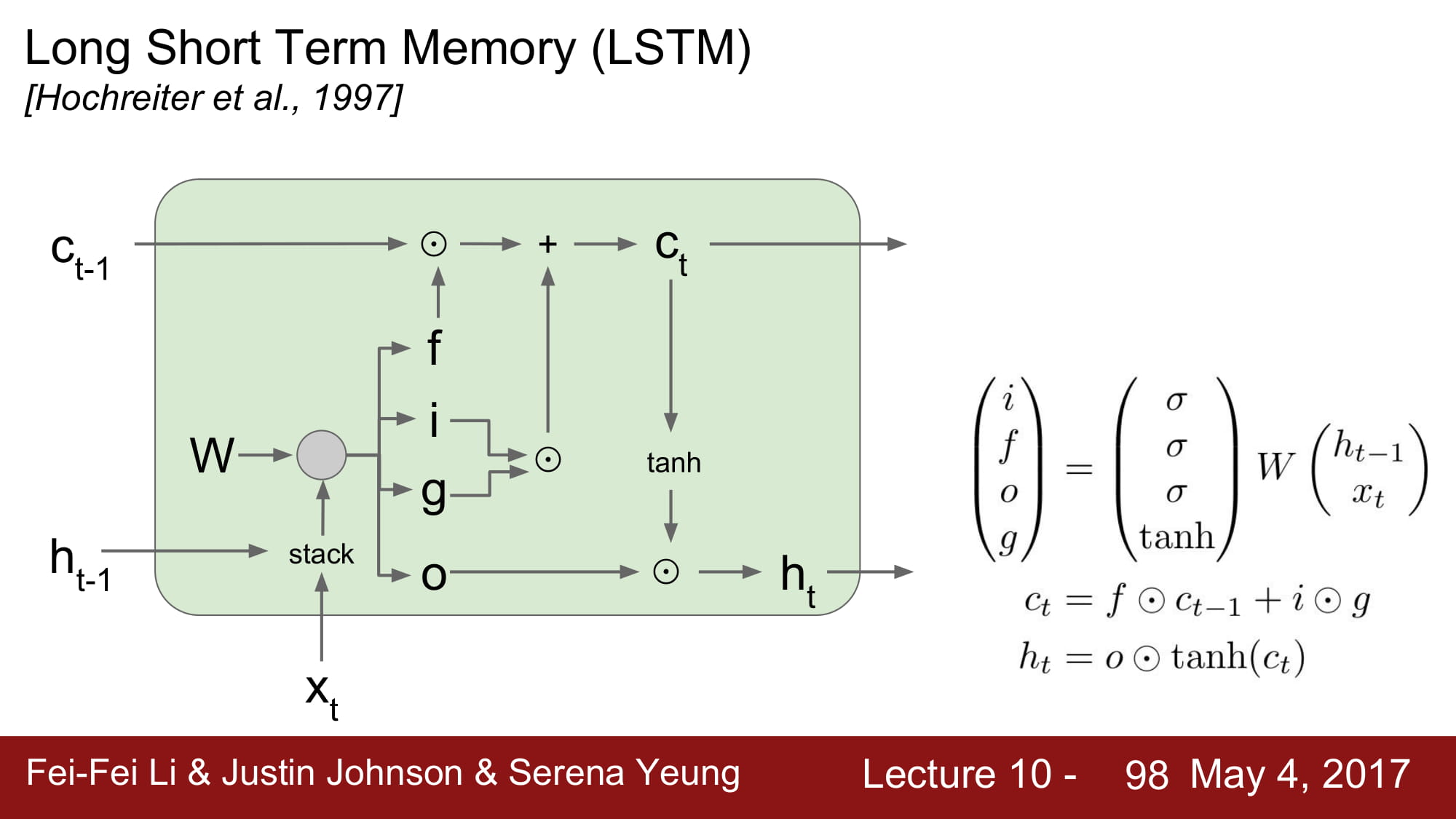
위와같은 아키텍쳐를 가지고, ifog, cell state, hidden state 모두 같은 크기를 가진다.
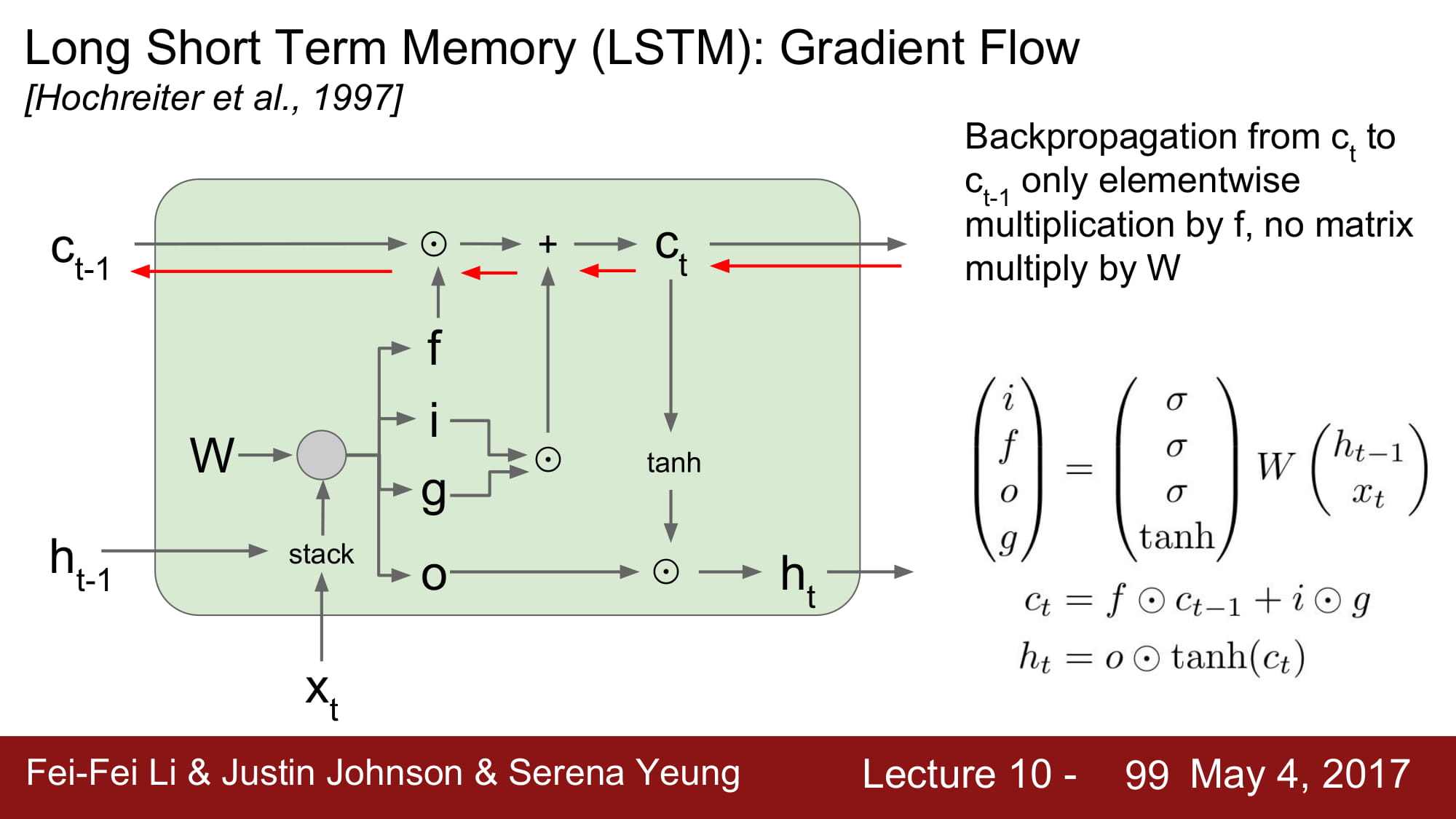
그럼 lstm 은 왜 좋은것일까?
back prop의 과정을 보면 매우 명확하다.
바로 cell state 를 통해서 gradient 를 뒤로 흘려줄 수 있게되는데, 여기서 cell state 는 오직 forget gate 와 pointwise multiplication 만 했다.
hidden state 의 local gradient 는 결국 ifog 로 부터 오는데, 이 gradient 들은 sigmoid, tanh 의 미분값으로 계산된다.
elementwise mulitplication 은 스칼라 편미분처럼 하면 된다.
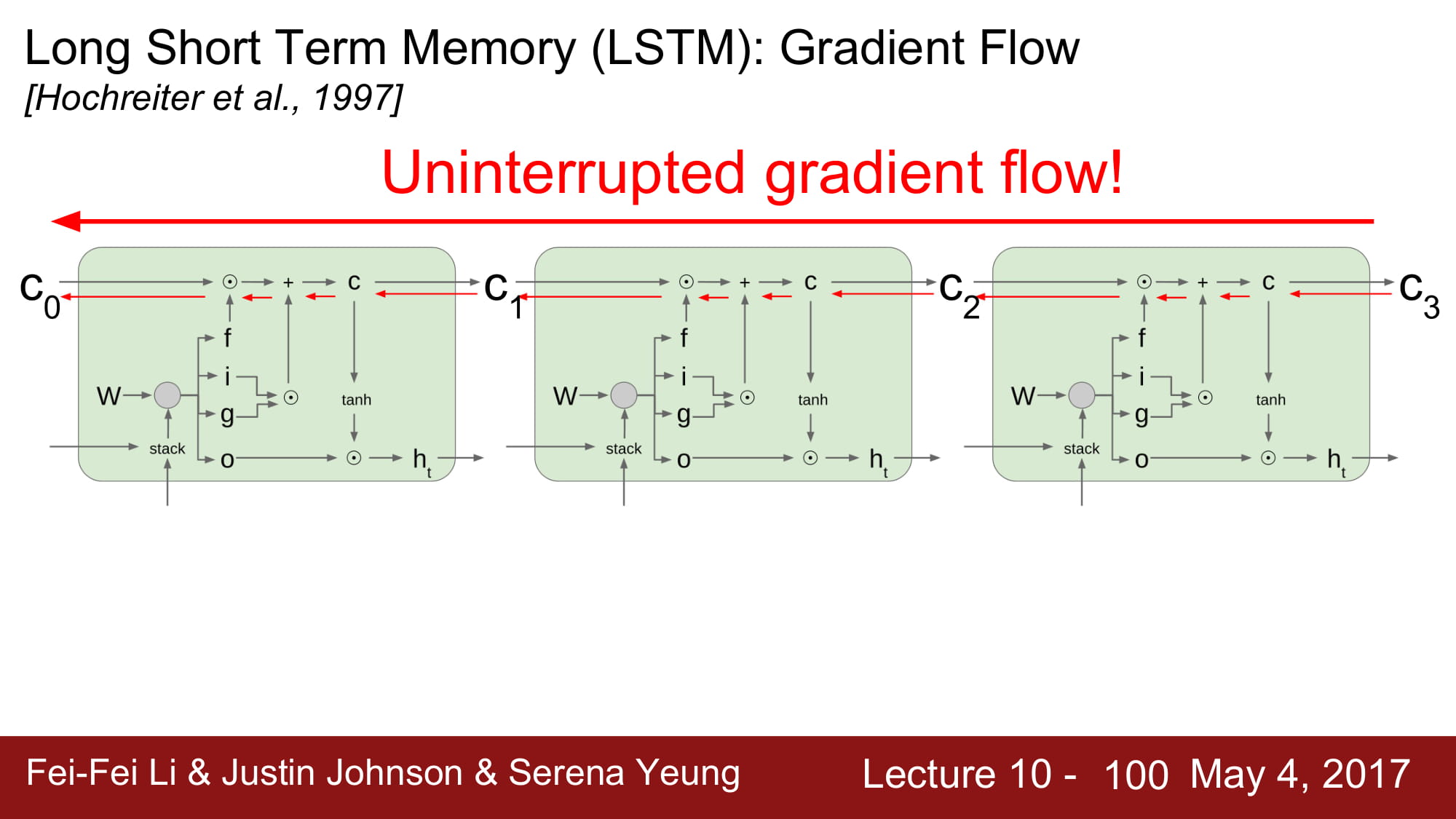
이렇게되면, gradient 가 쭉쭉 흐를수 있는 길이 만들어진다. gradient highway 가 만들어진것이다.
마치 고속도로가 만들어지고, 그 고속도로에서 국도가 나온 후 거기서 hidden state 가 계산되는거같은 매-직 이 펼쳐진다.
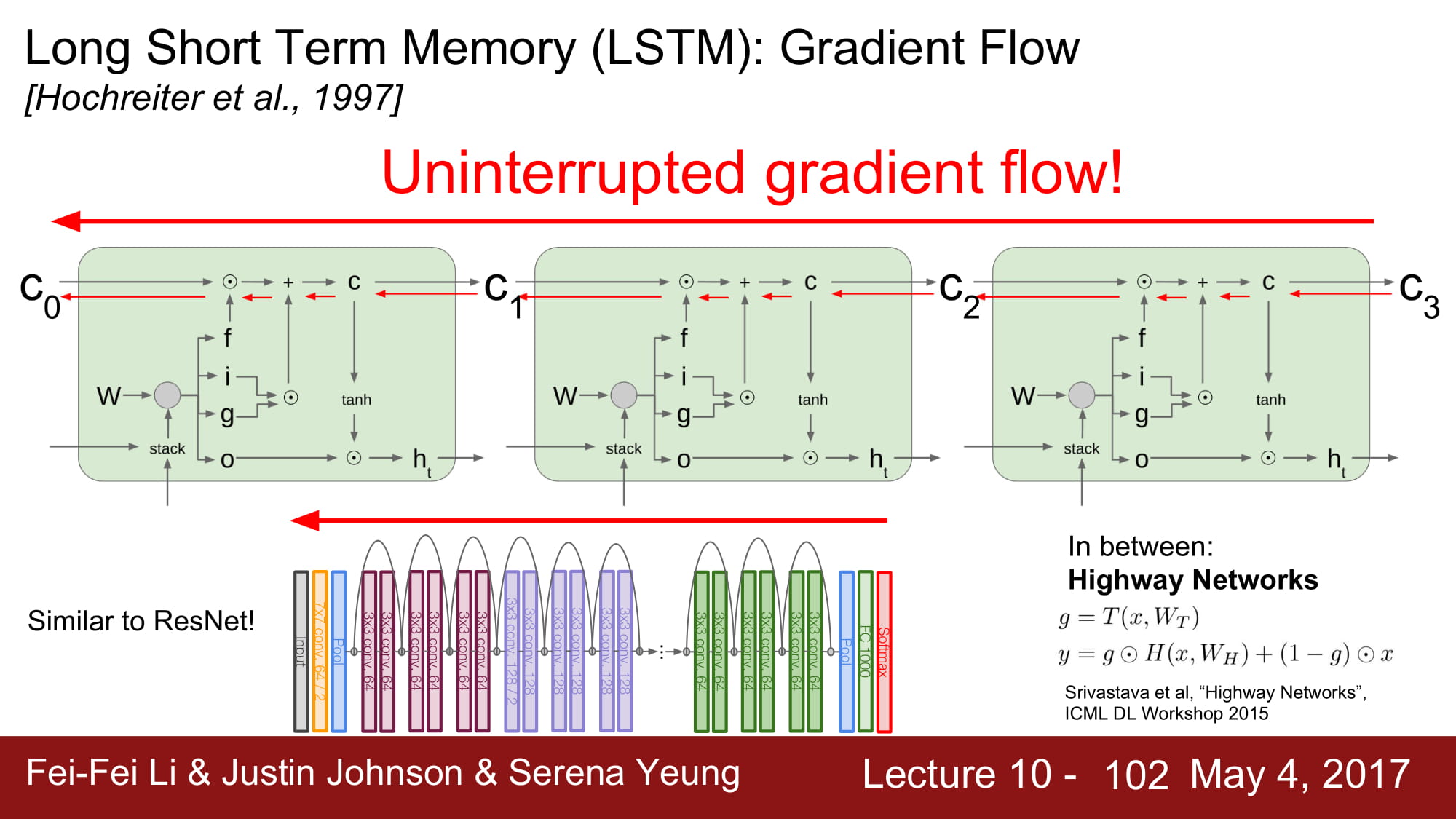
ResNet 도 gradient 가 지속적으로 흐를 수 있게 길을 만들어주었다. 비슷한 원리라고 한다.
ResNet 전에 말 그대로 Highway Network 라는게 있었다고도 한다.

그 외에 GRU 라는 친구도 있다한다.