Files: https://strutive07.github.io/assets/images/2_1_Fundamentals_of_Machine_Learning/IE661-Week_2-Part_1-icmoon-ver-1.pdf last update datetime: Dec 29, 2019 8:26 PM
Rule based machine learning
definition of machine learning
- 경험에 의해서 배울수 있는 프로그램
- 경험에 의해 performance가 올라가는 프로그램.
a perfect world for rule based learning
- Error가 없고, data는 noise-free, error-free 한 상태
- 확률적 상태가 없는 system. 모든 판단은 deterministic. ex) (그럴것 같기도 하고 아닌거 같기도 하고) 는 없음.
- 시스템을 재현하기 위한 모든 데이터가 있는 상태.
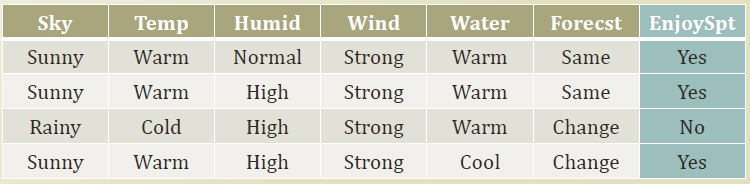
observation
Function Approximation
observation의 첫 번째 row 로 아래 특징들을 살펴보자.
- Instance X
- feature
- sunny, warm, normal, strong, warm, …
- 관측값
- label
- Y
- 관측값에 대한 결과(output)
- feature
- Training Dataset D
- instance의 집합
- Hypotheses H
- feature X 에서 정답 Y 를 맞출 수 있을법한 function를 추정하는것
- h(sunny, warm, X, X, warm) → Y
- 어떤 feature가 어떻게 해당 function에 영향을 주는지 알아내야함.
- Target Function C
- data를 통해서 추론하는 아직 알지 못하는 함수.
- feature 와 label 의 관계를 나타내는 function.
- 우리의 목표는 결국 H 중에서 알맞은 C 를 도출해내는것.
Graphical representation of function approximation
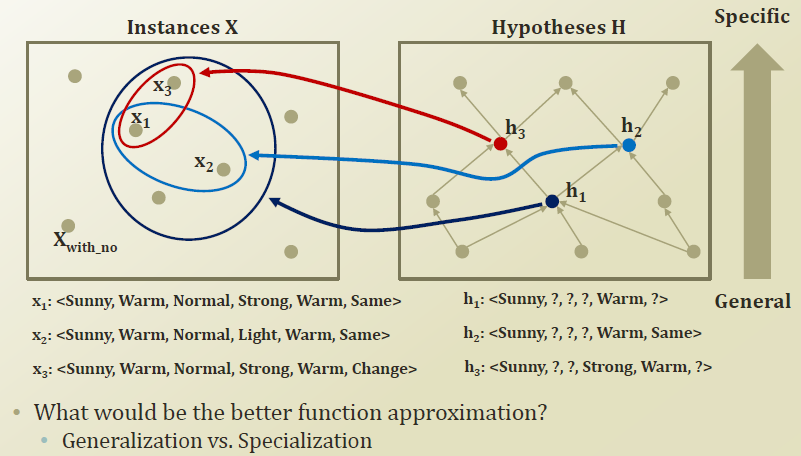
Instance space 와 Hypotheses space 를 그려보자.
각 hypotheses 에 부합하는 instance 의 관계를 보면, h1 은 h3 와 h2 를 포함하면서 더 넓은 영역을 YES 라고 판별하고있다.
즉 h1 은 h2, h3 보다 더 general 하다고 할 수 있고, h2, h2는 더 specific한 hypotheses 라고 할 수 있다.