Files: https://strutive07.github.io/assets/images/3_1_Optimal_Classification/IE661-Week_3-Part_1-icmoon-ver-1.pdf last update datetime: Jan 13, 2020 1:38 AM
Optimal classification
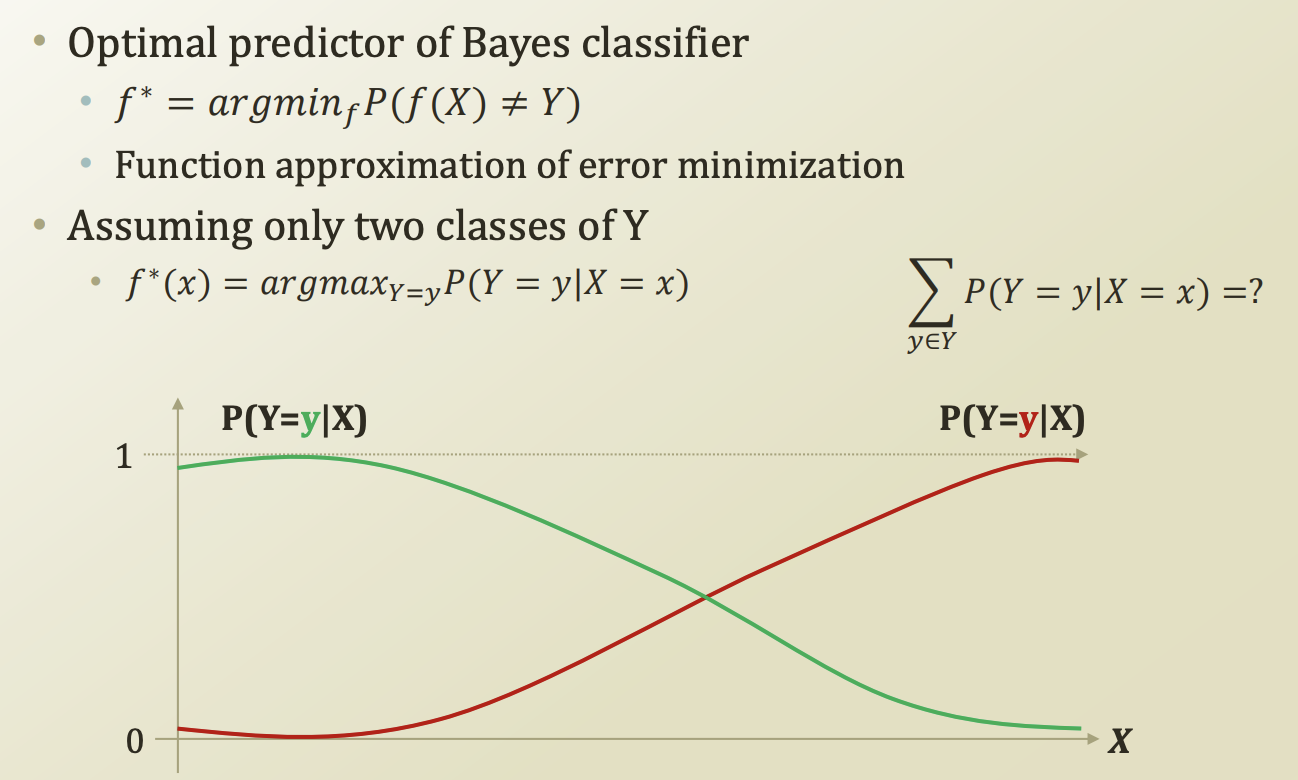
주어진 데이터에 대해서 최적의 결과를 도출해내는 function 을 찾는것이다. function은 error을 minimization 하는 방향으로 설계되어야한다.
X 값이 작을때는 초록색으로, X 값이 클때는 빨강색 값으로 판별하는것이 옳을것이다.
Bayes classifier
원본 데이터 Y 와 predict 한 데이터 f(X) 가 차이가 날 확률을 최소화 하는 함수를 근사해서 찾는것이다. 일종의 PAC learning이다.
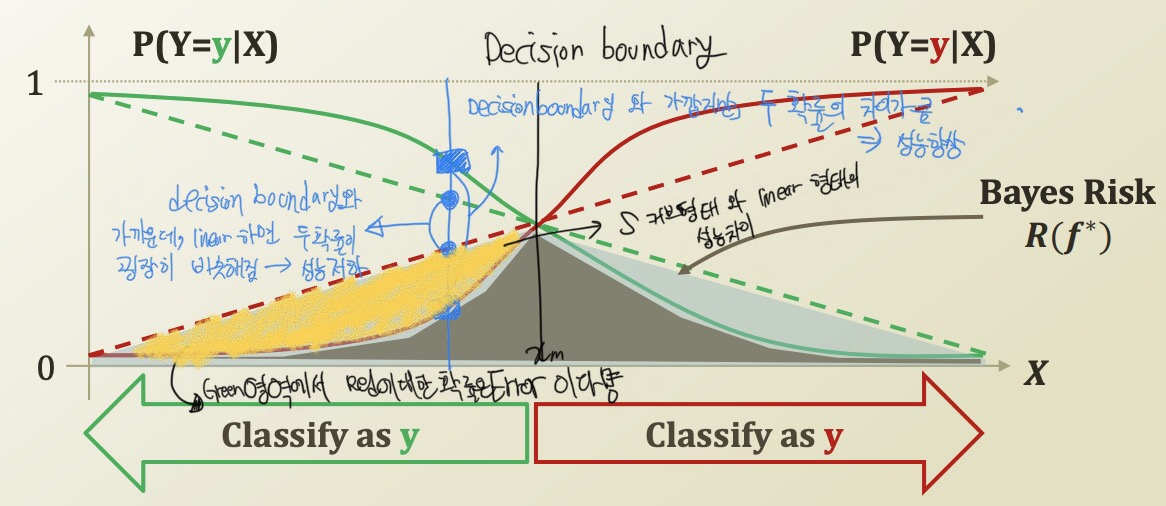
decision boundary 와 가까워질수록, 두 확률의 차이가 크지 않다면 이는 해당 class 를 명확히 분류할 수 없는 분류기가 된다.
예를들어, Green area에서 Green이라고 분류할 확률을 60%, Red 라고 분류할 확률을 40% 라고 한다면, 40%의 확률로 잘못 분류할것이다. 이를 bayes risk라고 한다.
Learning the optimal classifier

베이즈 이론으로 식을 변형시킨다.
Piror는 데이터셋에서 구할 수 있으므로 활용성이 높다. 어떻게? MLE, MAP 방법을 사용하면된다.

보통 Y, class 개수는 feature 인 X 보다 적으므로 단순하게 데이터에서 위 class conditional density, likelihood를 구할 수 있다.
그런데 feature X 하나만 놓고 prediction 하는것이 아니라, 여러가지 feature의 combination이 이루어질탠데, 이를 어떻게 표현할 수 있을까?
이 고민을 해결해주는것이 나이브 베이즈 classifier이다.