Files: https://strutive07.github.io/assets/images/3_2_3_3_Conditional_Independence_Naive_Bayes_Class/IE661-Week_3-Part_2-icmoon-ver-1.pdf last update datetime: Jan 13, 2020 1:42 AM
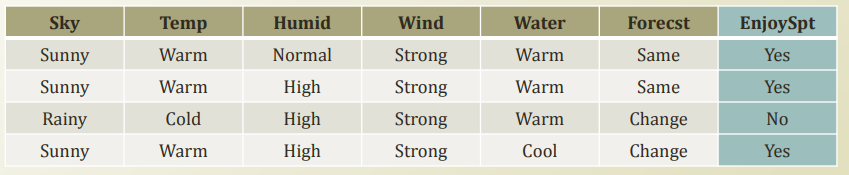

3.1에서 나왔던 결론을 다시 살펴보면, joint probability 를 구하는데 너무 많은 연산이 필요하다.

무려 이만큼의 경우가 존재한다.
Conditional independence
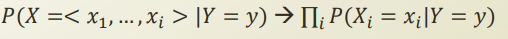
왼쪽 확률을 구하기 너무 힘드니, 각 feature 들이 독립적이라고 가정해보자.
각 feature들이 독립이지 않을 경우가 더 많을것이다. 하지만 이러한경우를 하나하나 다 계산하기 위해서는 2^d -1 의 corelation을 구해야 하므로, 너무 많은 연산이 든다. 따라서 이러한 정보를 배제하고 각 확률이 독립적이다 라고 가정을 하고 계산하는것이다.

x1 과 x2 가 conditional independence 하다면, x2의 유무에 상관없이 x1 given y 의 확률은 동일할것이다.
추가 정보) http://norman3.github.io/prml/docs/chapter08/2.html
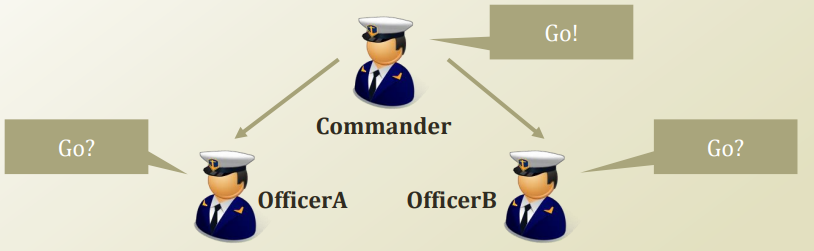
부모 노드가 관찰되지 않은 상태에서, 자식노드 A 와 B 자체는 독립적이지 않다.

하지만 만약 부모 노드 C 가 관찰되었다면?

| P(A | B, C) == P(A | C) 가 성립한다, 다시 말해, 부모 노드가 관찰되었다면, 자식 노드끼리는 서로 독립이 된다. 이를 조건부 독립 이라고 한다. |
나이브 베이즈 분류기는 부모 노드 C 를 class variable 인 Y 로 생각한 모델이다.
데이터상 Class variable 인 Y 도 관찰되어있으므로, 각 feature들은 조건부 독립이라고 생각하는것이다.
따라서 joint probability를 계산할 필요 없이 계산량을 확 줄일 수 있는것이다.
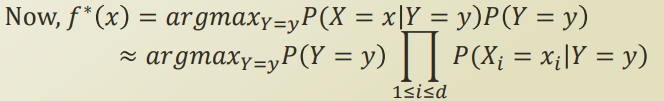
Conditional independent를 class variable Y와 X 의 관계를 ‘가정’ 한것이므로, 정확히 일치하지는 않는다. 이를 naive assumption 이라고 한다.
Problem of Naïve bayes classifier
각 feature 들에 correlation이 많을수록 나이브 베이즈 분류기의 성능은 떨어질 수 밖에 없다.
또한 한번도 관측되지 않은 데이터에 대해서는 잘못 판단할 수 있다. 이를 조금이나마 해결하기 위해 MLE 대신 MAP 를 활용해야한다. MLE 는 없는 정보에 대해서는 확률이 0이 되지만, MAP를 활용할경우 prior정보를 바탕으로 이를 막을 수 있다.