last update datetime: Feb 6, 2020 12:53 PM
Language Understanding
Paper
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Keywords
- Language Model
- deep bi-directional language model
Contribution
Computer Vision 분야에서는 ImageNet task로부터 많이 사용 되는 pre-trained 모델을 기반으로 transfer learning을 NLP 에도 깔끔하게 적용한것이다.
사실 이러한 시도는 NLP에서 굉장히 많았다. 왜냐하면, 기존 가지고있는 데이터셋으로는 Language model을 만들기 충분하지 않기 때문에, Wiki데이터 등으로 먼저 large dataset을 통해 언어의 특성을 학습하려는 시도는 있었다.
BERT는 transformer의 encoder network를 기반으로, self-attention을 이용하여 bi-directional 하게 언어 특성을 학습한다.
또한 MLM(Masked language model) 과 NSP(next sentence prediction) 방법을 사용하여 pre-training 하게 되고, 그 이후 많은 task에 token-base task인지, sentence-base task 인지 등등에 따라 여러 방식으로 fine-tuning을 진행할 수 있고 당시 수많은 task에서 SOTA를 차지했다.
Relative works
pre-training language representation에는 크게 feature-based approach와 fine-tuning approach가 존재한다.
- feature-based approach
- 예시) ELMO
- pre training 해둔 network의 일부를 가져와 다른 네트워크에서 feature로 사용.
- 예시) transformer encoder 의 특정 layer의 값을 모아 concat하여 사용
- fine-tuning approach
- 예시) OpenAI - GPT
- unlabeled text로부터 pre-training 시킨 모델에 새로운 network를 추가하여 supervised downstream task를 새로 학습시킴. 이 방식의 장점은, fine-tuning 할때 task에 맞게 적은 수의 parameter(FF layer 몇개 등등.. 간단한 layer)를 추가하여 새로 추가한 parameter부터 pre-trained model까지 fine-tuning함으로써 처음부터 학습시켜야하는 parameter의 수가 매우 적어진다(추가한 layer 만큼).
Architecture
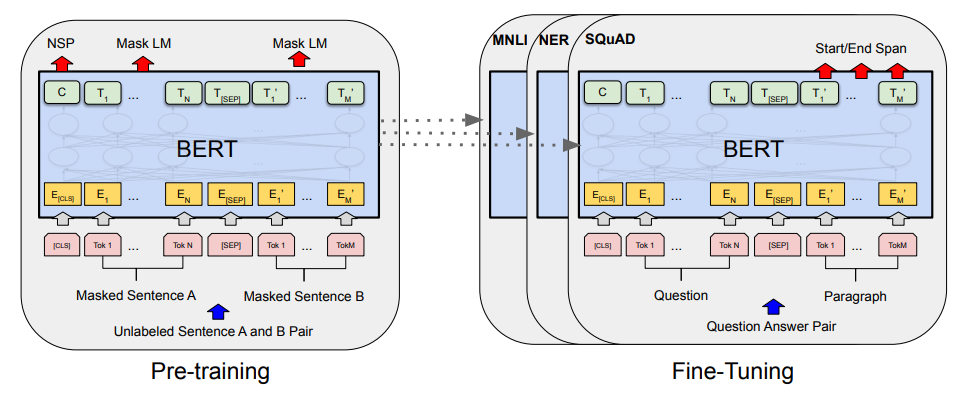
bert는 large dataset으로 pre training을 먼저 진행한 후, 각 task 에 맞게 fine-tuning 하는 방식으로 학습한다.
Input representation
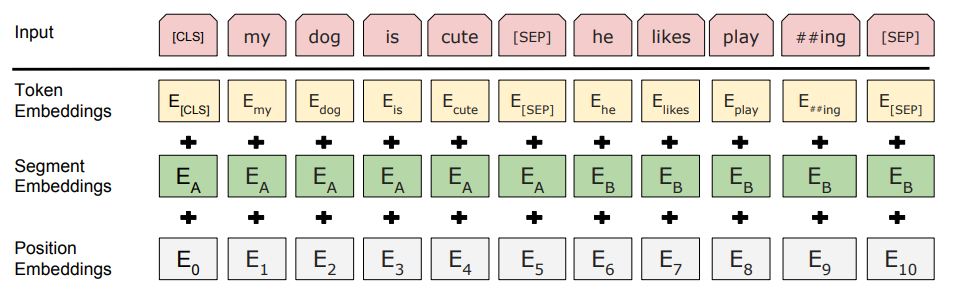
Input 은 Token embedding + Segment embedding + Position embedding 을 사용한다.
- CLS
- Input의 가장 첫 번째 token은 항상 CLS token으로 시작한다.
- CLS token과 짝을 이루는 마지막 transformer 의 hidden state 의 값은, classification task를 위해 sequence representation 정보를 aggregate 하고 있다.
- SEP
- BERT는 두 문장을 concat 하여 입력으로 사용한다. QA task를 위함이다. 따라서 concat 한 문장을 나눠주기 위해, 두 번째 문장의 바로 앞에 SEP를, 그리고 가장 마지막에 SEP 를 넣어준다.
- Token embedding
- Token embedding은 WordPiece(Wu et al., 2016) 를 사용한다. 30,000개의 token vocabulary를 사용했다고한다.
- Segment embedding
- 두 문장이 들어왔으므로, 어느 token이 A 문장인지, 어느 token이 B 문장인지 정보를 넣어주기 위해 A 문장에는 sentence A embedding을, B 문장에는 sentence B embedding을 넣어준다.
- Position embedding
- Transformer 논문에서 positional embedding을 사용한 이유는, RNN 등 sequenctial 모델을 사용하지 않고 한번에 input을 집어넣으면서 문장의 sequential한 정보를 잃어버릴 수 있기 때문에, input 자체에 position 정보를 넣어줘야한다.
- transformer 에서는 sin 과 cos 을 사용하여 encoding을 만들었다면, bert 에서는 embedding을 사용한다. lookup table에서 각 position의 vector들을 꺼내서 embedding에 추가해주는 형식이다.
class BertEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings.
"""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=0)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None):
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
device = input_ids.device if input_ids is not None else inputs_embeds.device
if position_ids is None:
position_ids = torch.arange(seq_length, dtype=torch.long, device=device)
position_ids = position_ids.unsqueeze(0).expand(input_shape)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + position_embeddings + token_type_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
위 구현체에서도 알 수 있듯이, embedding layer의 lookup table에서 값을 꺼내서 사용하는걸 알 수 있다.
positional embedding은 각 position에 대해, segment embedding은 각 문장의 type(A 인지, B 인지)에 따라 embedding vector를 부여한다.
Transformer encoder
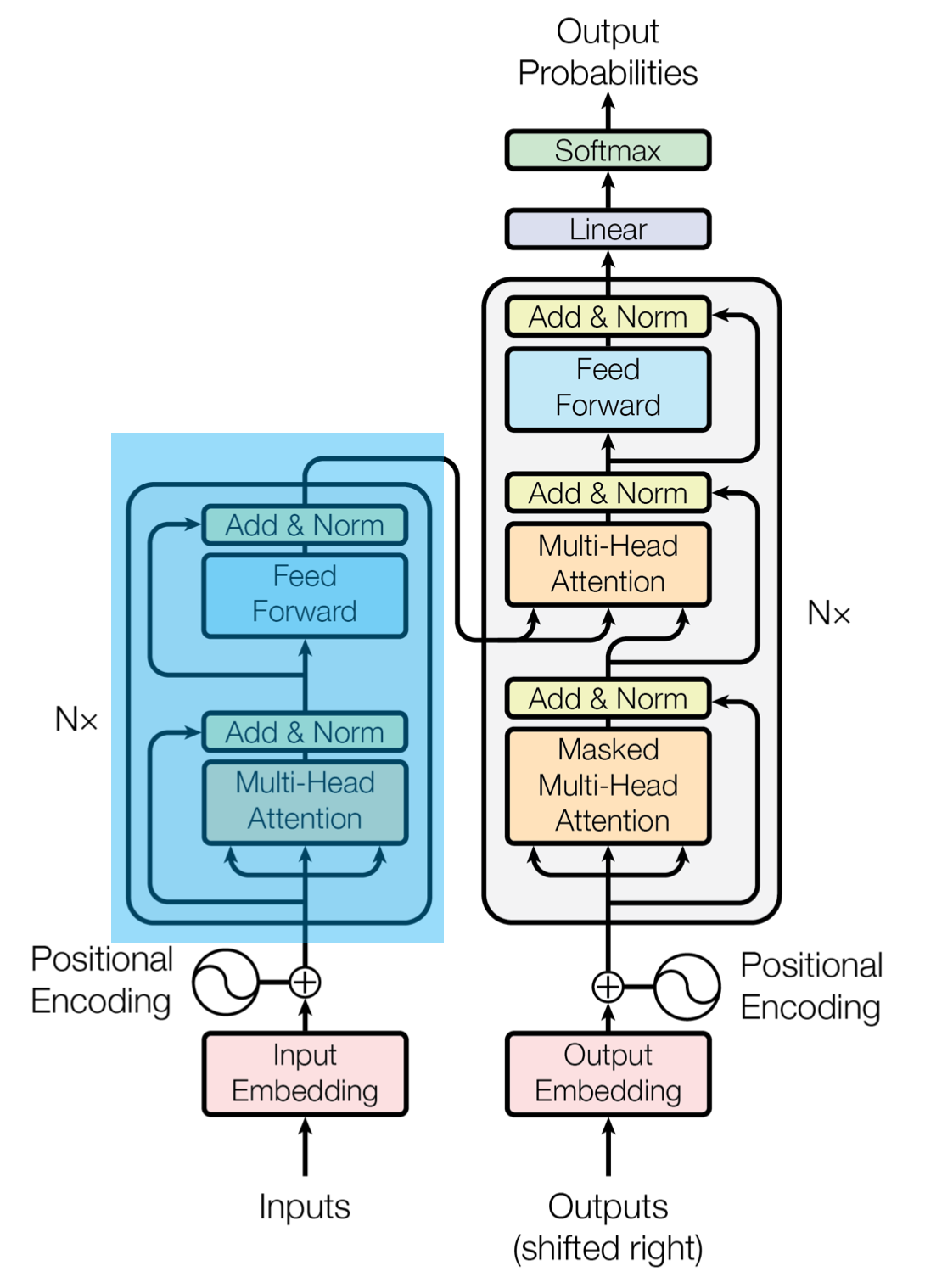
BERT 는 내부적으로 Transformer의 encoder를 사용한다. GPT에서는 Transformer의 decoder를 사용했었는데, BERT에서는 encoder를 기반으로 language model을 만드는것이 강점이 있다고 말한다.
이 이유는 decoder는 left to right로, 오른쪽 단어들의 context를 사용할 수 없다. BI-direction하게 학습할경우, 오른쪽 단어들의 context를 사용하여 language model을 만들 수 있다. 이는 Pre-training 방법에서 더 자세히 알아보자.
Pre-training - 1. Masked language model
Deep bi-directional language model을 학습하기 위해, BERT 는 Masked language model 이라는 방식을 사용한다.
일부 단어를 랜덤하게 [MASK] Token 으로 변경하는것이다. 15%의 token을 MASK 로 바꾸는 작업을 하고, 이 15%는 다음과 같은 masking rule을 따른다.
-
80% 는 정말
[MASK]로 바꾼다my dog is hairy → my dog is [MASK]
-
10% 는 다른 random한 단어로 변경한다.
my dog is hairy → my dog is apple
-
10% 는 바꾸지 않는다. 바꾸지 않는 이유는 올바르게 단어를 관측한경우를 학습하기 위함이다.
my dog is hairy → my dog is hairy
이 방식의 이점은, model은 어떤 단어가 원본이고, 어떤 단어가 MASK 이고, 어떤 단어가 random changed 된 단어인지 모른다는것이다. 따라서, 모델은 모든 input token에 대해서 distributional contextual representation을 유지하도록 강요받게된다.
또한 전체의 1.5% token만 random changed 되었으므로, model 이 dataset에 의해 language 를 잘못 이해할 경우도 없다고 한다.
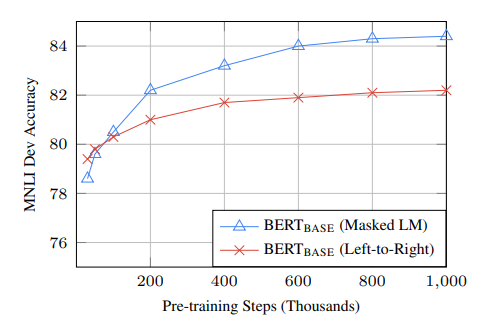
또한, MLM은 기존 left to right LM (LTM LM) 보다 converge 하는데 더 많은 시간이 소요되지만, 기존 LTM LM 보다 MLM 이 더 빠르게 좋은 성능을 보인다고 한다.
google-research tensorflow 1.x 구현체
def create_masked_lm_predictions(tokens, masked_lm_prob,
max_predictions_per_seq, vocab_words, rng):
"""Creates the predictions for the masked LM objective."""
cand_indexes = []
for (i, token) in enumerate(tokens):
if token == "[CLS]" or token == "[SEP]":
continue
if (FLAGS.do_whole_word_mask and len(cand_indexes) >= 1 and
token.startswith("##")):
cand_indexes[-1].append(i)
else:
cand_indexes.append([i])
rng.shuffle(cand_indexes)
output_tokens = list(tokens)
num_to_predict = min(max_predictions_per_seq,
max(1, int(round(len(tokens) * masked_lm_prob))))
masked_lms = []
covered_indexes = set()
for index_set in cand_indexes:
if len(masked_lms) >= num_to_predict:
break
# If adding a whole-word mask would exceed the maximum number of
# predictions, then just skip this candidate.
if len(masked_lms) + len(index_set) > num_to_predict:
continue
is_any_index_covered = False
for index in index_set:
if index in covered_indexes:
is_any_index_covered = True
break
if is_any_index_covered:
continue
for index in index_set:
covered_indexes.add(index)
masked_token = None
# 80% of the time, replace with [MASK]
if rng.random() < 0.8:
masked_token = "[MASK]"
else:
# 10% of the time, keep original
if rng.random() < 0.5:
masked_token = tokens[index]
# 10% of the time, replace with random word
else:
masked_token = vocab_words[rng.randint(0, len(vocab_words) - 1)]
output_tokens[index] = masked_token
masked_lms.append(MaskedLmInstance(index=index, label=tokens[index]))
assert len(masked_lms) <= num_to_predict
masked_lms = sorted(masked_lms, key=lambda x: x.index)
masked_lm_positions = []
masked_lm_labels = []
for p in masked_lms:
masked_lm_positions.append(p.index)
masked_lm_labels.append(p.label)
return (output_tokens, masked_lm_positions, masked_lm_labels)
Pre-training - 2. Next Sentence Prediction
QA, Natural language interface 등의 task 에서는, 두 문장 사이의 관계를 이해하는것이 중요합니다. 하지만 위의 MLM 을 사용하면 token level 까지만 학습이 되기 때문에 sentence level의 정보를 추가할 필요가 있습니다.
BERT 는 이를 두 문장이 이어져 있는지, 아닌지를 판별하는 binary classification 문제로 치환하여 해결합니다.
두 문장이 원본 데이터에서 원래 이어져 있는 문장이면 label을 IsNext로, 랜덤하게 서로 붙인 문장이면 label을 NotNext 로 판별하도록 하는것입니다. 확률은 50% 로 랜덤하게 데이터를 생성합니다.
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks
by concatenating and adding special tokens.
A BERT sequence has the following format:
single sequence: [CLS] X [SEP]
pair of sequences: [CLS] A [SEP] B [SEP]
"""
if token_ids_1 is None:
return [self.cls_token_id] + token_ids_0 + [self.sep_token_id]
cls = [self.cls_token_id]
sep = [self.sep_token_id]
return cls + token_ids_0 + sep + token_ids_1 + sep
google-research tensorflow 1.x 구현체
def create_instances_from_document(
all_documents, document_index, max_seq_length, short_seq_prob,
masked_lm_prob, max_predictions_per_seq, vocab_words, rng):
"""Creates `TrainingInstance`s for a single document."""
document = all_documents[document_index]
# Account for [CLS], [SEP], [SEP]
max_num_tokens = max_seq_length - 3
# `max_seq_length` is a hard limit.
target_seq_length = max_num_tokens
if rng.random() < short_seq_prob:
target_seq_length = rng.randint(2, max_num_tokens)
instances = []
current_chunk = []
current_length = 0
i = 0
while i < len(document):
segment = document[i]
current_chunk.append(segment)
current_length += len(segment)
if i == len(document) - 1 or current_length >= target_seq_length:
if current_chunk:
a_end = 1
# 전체 sequence를 사용하지 않는다. random하게 sentnece를 잘라서 넣는다. 단순하게 두 문장을 concat하면
# next sentence prediction이 너무 쉬워지기 때문이다.
if len(current_chunk) >= 2:
a_end = rng.randint(1, len(current_chunk) - 1)
tokens_a = []
for j in range(a_end):
tokens_a.extend(current_chunk[j])
tokens_b = []
# Random next
# 50%의 확률로 Random sequence를 붙임.
is_random_next = False
if len(current_chunk) == 1 or rng.random() < 0.5:
is_random_next = True
target_b_length = target_seq_length - len(tokens_a)
for _ in range(10):
random_document_index = rng.randint(0, len(all_documents) - 1)
if random_document_index != document_index:
break
random_document = all_documents[random_document_index]
random_start = rng.randint(0, len(random_document) - 1)
for j in range(random_start, len(random_document)):
tokens_b.extend(random_document[j])
if len(tokens_b) >= target_b_length:
break
# We didn't actually use these segments so we "put them back" so
# they don't go to waste.
num_unused_segments = len(current_chunk) - a_end
i -= num_unused_segments
# Actual next
# 50%의 확률로 실제 다음 sequence를 붙임
else:
is_random_next = False
for j in range(a_end, len(current_chunk)):
tokens_b.extend(current_chunk[j])
truncate_seq_pair(tokens_a, tokens_b, max_num_tokens, rng)
assert len(tokens_a) >= 1
assert len(tokens_b) >= 1
# Seq A와 seq B 붙이기
tokens = []
segment_ids = []
tokens.append("[CLS]") # 가장 앞에는 CLS token
segment_ids.append(0)
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
tokens.append("[SEP]") # 문장 사이에 SEP token
segment_ids.append(0)
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
tokens.append("[SEP]") # 2번째 문장 마지막에 SEP token
segment_ids.append(1)
두 구현체가 조금 구현이 다르다. google research는 문장 전체를 사용하는것이 아니라, 문장의 일부분만 잘라서 사용한다. 그냥 붙이면 task가 너무 쉬워져서 그런다고 한다.
We DON’T just concatenate all of the tokens from a document into a long sequence and choose an arbitrary split point because this would make the next sentence prediction task too easy. Instead, we split the input into segments “A” and “B” based on the actual “sentences” provided by the user input.
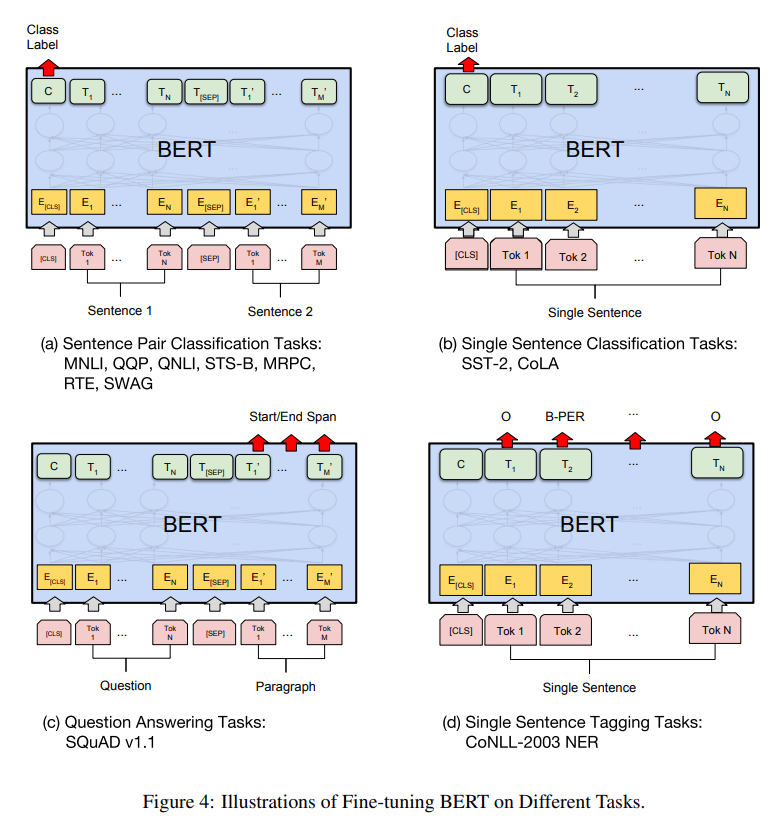
Fine-tuning BERT
각 task에 맞게 input 과 output sequence 를 조정해주고, 마지막 transformer layer 의 hidden state들을 어떻게 새로운 fine-tuning용 layer들과 연결해줄지만 결정한다면, 쉽게 fine-tuning 될것이다.
Sequence tagging 이나 question answering 같이 token-level task 들의 경우, 마지막 transformer layer의 token 들을 사용하여 fine-tuning 한다.
Sentence Classification, sentiment analysis 등의 sentence-level classification task 들은 마지막 layer의 CLS token의 hidden state를 fine-tuning에 이용한다.
Pretraining과 비교했을때, fine-tuning은 매우 빠르게 학습된다.
Hyperparameter는 task 마다 다르지만, 아래 hyperparemeter들은 대부분 task 에서 잘 작동했다한다.
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 2, 3, 4
또한, dataset의 크기가 클수록 hyperparameter에 덜 민감하다고 한다.
각 task들의 활용방법은 아래 Experiments에서 설명할 예정.
Experiments
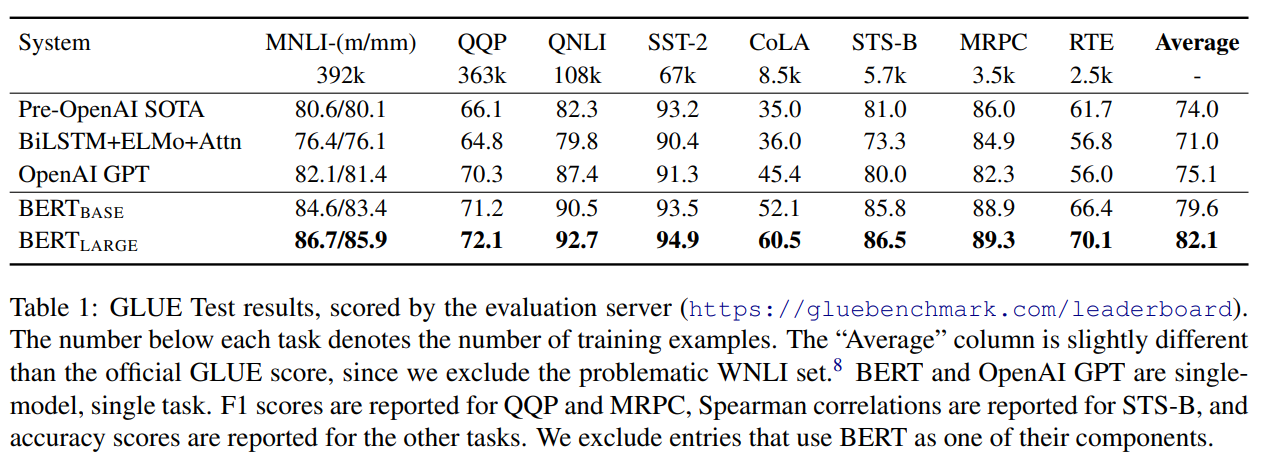
GLUE
GLEU benchmark는 다양한 natural language understanding task를 모아둔것이다.
GLEU에 fine-tuning 하기 위해, CLS token에 해당하는 마지막 transformer layer의 hidden state를 이용한다. 이는 문장의 정보를 함축하고있는 hidden state 이다.
Fine tuning 을 위해 classification layer를 추가해준다. Weight 는 Class 수 K * hidden state 크기 만큼의 차원을 가진다.
그 이후 Loss 는 softmax 로 계산한다.
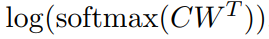
그 결과는 모든 task 에서 당시의 SOTA를 갱신한다.
SQuAD v1.1
SQuAD v1.1 dataset은 Question Answering dataset으로, question/answer pair를 가진 dataset이다.
이번에는 GLEU 를 fine-tuning 할때와 방식이 조금 다르다. BERT 는 question 과 answer 를 하나의 single sequence 로 묶어서 input으로 만든다. 따라서 BERT 는 어느 토큰부터 어느 토큰까지가 answer 의 영역이야? 라는 형식으로 answer 를 찾아낸다.
answer 의 시작을 token S 라고 하고, answer 의 끝을 token E 라고 하자. 이 두 parameter는 fine-tuning시에 학습된다.
마지막 transformer layer의 hidden state 들 중, 특정 token_i이 start token이 될 score는 start token S 와 token_i 를 dot product 한 결과로 나타낸다. End token도 마찬가지 방식으로 dot product 를 진행한다. 그 이후 해당 score을 softmax 를 통과시켜 확률로 변환하고, 가장 높은 값을 찾아낸다.
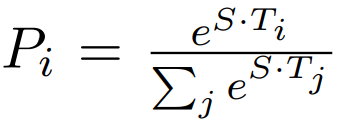
start token S 로 부터 end token E 까지가 answer 일 score 는 S·Ti + E·Tj 로 계산된다.
그리고 j ≥ i 인 후보 중에서, 가장 값이 큰 <i, j> 쌍을 answer 의 영역으로 predict 한다.
Loss 는 올바른 start 와 end position에 대한 sum of log-likelihoods 를 사용한다.
google은 3epoch, learning rate 5e-5, batch size 32 를 사용했다 한다.
SQuAD v2.0
SQuAD v2.0 은 1.1 과 유사하지만, 대답할 수 없는 질문 이 포함된 dataset 이다. BERT 는 대답이 불가능한지 여부를 CLS token을 이용했다.
start token 과 end token의 계산을 CLS token C 까지 확장 시킨다.
그리고, 대답 불가능 할 경우를 다음과 같이 계산한다.
그리고, 대답 가능한경우 answer 의 영역은 1.1과 동일하게 계산한다.
마지막으로, 대답 가능한 경우는 S_ij 가 S_null 보다 큰 경우, 대답 불가능 할 경우는 S_null이 더 클 경우로 판단한다.
이 수식에서 상수 r 이 추가된다. 이는 threshold로 활용된다.
SWAG
The Situations With Adversarial Generations (SWAG) dataset은 앞 문장이 주어지고, 보기로 4 문장이 주어진다. 그 주어진 문장중에서 가장 잘 어울리는 문장을 찾는 task 이다.
Fine tuning 하기 위해, 앞 뒤 문장중 가능한 문장들을 묶어 하나의 데이터로 만든다. 이때 앞 문장을 embedding A, 뒤 문장을 embedding B로 한다.
그 이후 GLEU 를 학습할때와 동일하게 CLS token 에 대응하는 token C 와 task-specific 한 새로운 parameter 를 dot product 한다. 이를 score 로 삼고, softmax 로 normalize 한다. softmax 가 만든 확률로 classification을 진행한다.
Ablation studies
Effect of Pre-training tasks
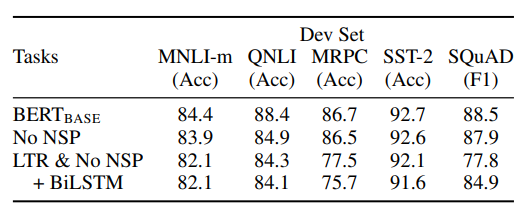
이번에는 BERT 모델에서 NSP를 제거해보고, bi-direction을 제거해보는등의 실험을 해본다.
위 표에서도 볼 수 있듯이, NSP를 제거하면 NLI 계열 task 에서 큰 성능 하락이 보인다. 따라서 NSP task가 sentence level에서 언어 구조를 파악하는데 큰 도움을 주고 있다는 것을 알 수 있다.
이번에는 bi-direction을 제거하고, left to right 로 학습해본다. 이때도 전체적으로 성능이 하락하는것을 알 수 있다.
심지어, BiLSTM 을 붙여 어느정도 bi-direction 성질을 주어도, 이는 left to right, right to left 를 concat 하여 사용하는 shallow bi-directional language model 이기 때문에 성능이 떨어진다.
따라서 BERT 에서 제안한 deep bi-directional language model 이 큰 영향을 가진다는것을 알 수 있다.
Effect of Model size
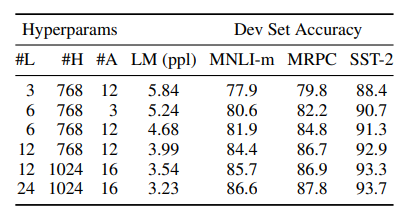
모델이 커질수록, 정확도가 상승함을 알 수 있다.
특히, pre-training에서 큰 모델을 사용했기 때문에, fine-tuning시 작은 dataset을 사용해도 어느정도 정확도를 보장해줄 수 있다.
Feature-based Approach with BERT
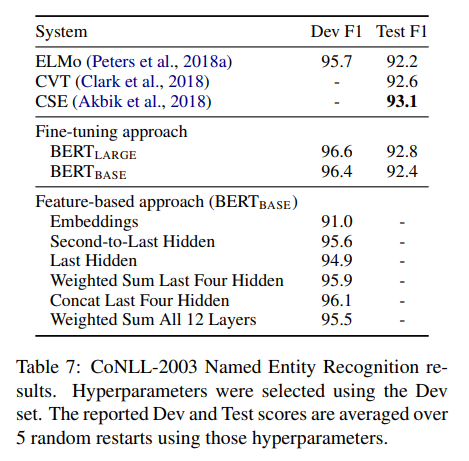
BERT 의 fine-tuning은 많은 NLP task를 해결했지만, fine-tuning으로 모든 문제가 해결되는것은 아니다. 또한 pre-training 한 parameter를 더 학습하지 않고 사용할 경우 computational benefit을 얻을 수 있다.
BERT 의 특정 transformer layer과 추가적인 LSTM layer를 활용하여 NER(Named entity Recognition) 사용하는 방식을 실험해보았다.
위와같이 좋은 성능을 가지는것을 알 수 있다.
Ablation for different masking procedures
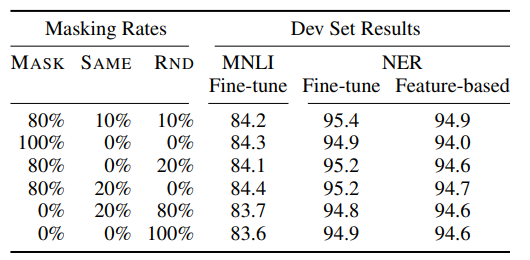
80:10:10이 나온 실험을 설명해준다.
전체적으로 fine-tuning task 가 feature-based 보다 좋은 성능을 가지고 있음을 알 수 있다. 또한 오직 random chang 만, mask 만 사용하는것보다, mask 와 same 을 섞어주는것이 더 좋은 성능을 가지는것을 알 수 있다.