Files: https://strutive07.github.io/assets/images/6_1_Over_fitting_and_Under_fitting/IE661-Week_6-Part_1-icmoon-ver-1.pdf last update datetime: Mar 07, 2020 1:43 PM

accuracy 만이 머신러닝 모델의 정확도를 표현할 metric 일까? task 마다 다르다. precision, recall, r-measure 등이 있다.

머신러닝의 아킬레스건은, 학습 데이터의 분포와 미래의 실제 데이터의 분포가 일치하거나, 매우 유사해야한다는것이다. 계속 분포가 변한다면 online learning 등의 학습 기법을 사용해야한다.
하지만 학습 데이터와 미래의 실제 데이터의 분포는 같지 않은 경우가 대부분이다.
따라서, 학습 데이터에 overfitting 할 경우, 학습 데이터에만 존재하는 out lier 들에 집중하여, 예를들어 SVM 에서 차수를 매우 많이 올려 non-linearity 를 최대한 높여서 out lier 를 잘 predict 한다 해도, 오히려 실제 데이터에 이 모델을 적용할 경우 그 극심한 non-linearity, overfitting 된 모델은 잘 작동하지 않을것이다.
그럼 overfitting을 어떻게 detect 할 수 있 을까?
학습 데이터를 training dataset 과 testing dataset으로 나누는 방법이 있다.
training dataset에 과적합될경우, training dataset에서 없던 데이터 분포인 test dataset에서 좋지 않은 성능을 낼것이기 때문에 overfitting을 감지할 수 있다.
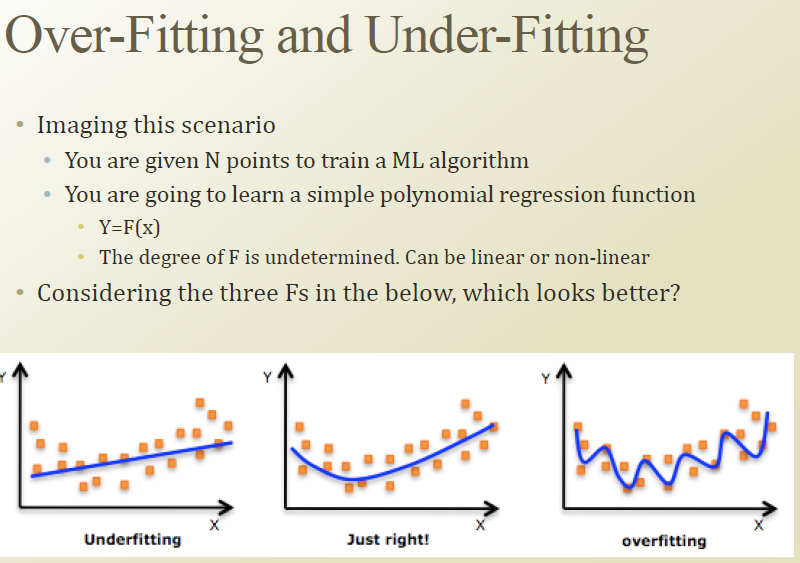
overfitting은 차수가 너무 높아 training data에 너무 fitting 된 상태
underfitting은 차수가 너무 낮아 training data를 학습에 다 사용하지 못한 상태
그 중간 어딘가에 just fit 된 모델을 찾아내는것이 중요함.